

News from Industry
How to add virtual background transparency in WebRTC
There is a cool new feature everyone has been trying to implement – background transparency. Virtual backgrounds have been around for a while. Rather than inserting a new background behind user(s), transparency removes the background altogether, allowing the app to place users over a screen share or together in a shared environment. There doesn’t seem […]
The post How to add virtual background transparency in WebRTC appeared first on webrtcHacks.
Twilio Signal 2021: A Pivot from CPaaS to Customer Engagement Platform
Twilio Signal 2021 defines Twilio as “API”, “programmable”, “platform” and “customer engagement”. Here’s how it intends to compete in its many markets.
Twilio Signal 2021 is when Twilio officially pivoted from CPaaS to a Customer Engagement Platform. This is the reason Twilio acquired Segment last year, and the explanation of how it intends to leverage that acquisition.
Every year, I put time aside for Twilio Signal. Either in person or remote, going through the sessions and paying extra attention during the keynote. This has developed into a comprehensive view and research resources about Twilio that I’ve put up. It is time now to review what we had at Twilio Signal 2021.
Table of contents- Twilio Signal Keynote 2021
- Defining Twilio in 2021
- Twilio by the numbers
- The Pivot: Twilio Customer Engagement Platform
- Twilio Signal 2021 keynote announcements
- Regional Twilio
- Twilio MessagingX
- Twilio Voice and IVR Now
- Twilio Intelligence
- Twilio Flex
- Segment
- Announcements that didn’t make it into the keynote
- What Twilio isn’t
- What’s next for Twilio?
Twilio didn’t put the keynote for Signal 2021 on YouTube (yet), but they did have it as part of their all-day Signal TV session. The video below will get you the keynote, which was around 90 minutes long:
As events go, Twilio Signal 2021 was quite a good experience for a virtual event. It was a bit hybrid, but most of the focus and action took place on the virtual side of it (or at least felt that way for me as a virtual audience).
Defining Twilio in 2021Twilio never liked or used the term CPaaS. I am not really sure why.
The Twilio pivotThere were 4 words that came time and time again during the keynote, and I think they are the center of what Twilio gravitates around today: “programmable”, “platform” and “customer engagement”.
Everything Twilio does can be found around these words, and I believe also every type of adjacent business they will try to go after will have two or more of these words in them in one way or another.
Twilio tried to show this shift and to move away a bit from APIs. It will take more than a single Signal event to do that.
Jeff Lawson, Co-founder and CEO of Twilio, started by presenting the idea of Customer Engagement and ended the keynote with the Customer Engagement Platform taking us in a complete circle around it.
Why did Twilio pivot now?Twilio is the leader in CPaaS. It has been so for many years now, defining and redefining what CPaaS is. Twilio is also ahead of all of its competitors. Way ahead. It acts as a best of suite provider, which covers most if not all of what CPaaS is, with depth of functionality in many of its offerings.
As such, it sees and knows the market. It also knows the market’s limits. Which means it understands its estimated growth. It had to pivot and start eating up more adjacencies to continue growing at an accelerated rate. But there probably aren’t enough adjacencies it can go after that can be defined as CPaaS or as communication APIs. So they went up the food chain, marketing customer engagement as their target.
How Twilio’s breakout acquisitions into email and customer data enabled the pivot to Customer EngagementTwilio’s reasoning for doing it now?
- Size of the market. The communication market has been said to be $1T. Twilio believes it is much bigger, due to the slower shift of communications towards the cloud and the fact that communication is now used in new ways, not attributed in the original market sizing made by analysts
- Architectural shift. The shift to the cloud. This one is driven by customers who need to do more, faster and more flexibly. Legacy vendors can’t do it, while Twilio as a cloud native vendor can offer such capabilities
- A focus on “proactive”. Most use cases in business communication so far have been reactive in nature. Now they are a lot more proactive. That shift requires new capabilities, ones that require access to more data and being smart about it
To be frank, the architectura shift as well as the move from reactive to proactive have been industry themes for over 10 years. The pandemic simply accelerated these changes, and probably accelerated Twilio’s own pivot. It is also a new language that Twilio is now speaking, so we hear it from them as well.
Twilio by the numbersEach time, Jeff starts his keynote with numbers, showing off Twilio’s size. It is interesting each time to see which numbers he shares and highlights at the beginning of the keynote. This year?
Twilio Signal 2021 numbers versus 2019 & 2020{kind=link}
What numbers did Twilio share in the beginning of its keynote this year versus previous years?
201920202021Customers160,000200,000+240,000+ in 180+ countriesText messages––128B (100% growth)Emails––1T (5.8B single day peak)Calls––25BFlex interactions––0.5BSegment data events––10TInteractions750B1T–Unique phone numbers2.8B3B–Calls/minute32,500––Peak SMS/second13,000––Email addresses3B/quarter50%–Video minutes–3B–Developers6M––This is in-line with its pivot, as many of the original numbers aren’t even mentioned.
So… Twilio is now even bigger, and it is pivoting.
- Customers came first. Not as a number, but as logos, showing how strong and diverse Twilio’s customers are
- It was important for Jeff to share that these customers include startups, enterprises and ISVs – Twilio isn’t catering only startups
- I think it was the first time Twilio shared the countries of origin for its customers. 180 of them. With anywhere between 195 to 249 (depending who is counting), that’s quite impressive. The reason to share this number? To signal that Twilio isn’t only big, but it is big everywhere (ie, outside the US)
- Text is still the most important thing for Twilio. Not as SMS, but as “text” – omnichannel. We will see later that this still means SMS
- For calls, Twilio shared the number of calls and not peak, with 25B as that number
- Flex interactions. For the life of me, I still can’t understand what interactions are, and probably no one does. Twilio simply wanted to say “Flex is a real and it is big” – to remove the doubt in the business success of Flex in the contact center space
- Segment data events are… as bad as Flex interactions as numbers go – I don’t understand what that means. But saying 10T is always good, cementing Twilio’s “dominance” on the CDP (Customer Data Platform) space Segment belongs to
I haven’t added the social good related numbers that Twilio shared not because they aren’t important, but because they require a separate mention.
Twilio made the decision years ago to be a company that does good in the world. It also decided to put its money where its mouth is, through its twilio.org operation and its shift to become a diversified company.
Time is spent each year at Signal during the keynotes as well as in specific sessions for social good, and this year was no different.
Twilio and partnershipsJeff mentioned the strategic partners of Twilio at the beginning as well. These are getting more important to Twilio as it grows and shifts towards customer engagement.
Twilio dogfoodingTwilio is dogfooding its own products. For Twilio Signal 2020 and 2021 it has been hard at work building its own hybrid events platform. Still at its early stages but quite commendable.
{kind=link}
Each year, additional pieces of the Twilio building blocks are being used to create these events. It will be interesting to see if in 2022 they will continue with this trend or go to a live-only event. Another question is if and when will they productize this as a programmable events platform.
The Pivot: Twilio Customer Engagement PlatformAfter the numbers it was time for the pivot. This is where Twilio moved away a bit from its roots into communications towards custom engagement. And the way this is explained by the fact that Twilio now isn’t only about communications but about all experiences with customers. Customers “drove” Twilio there, which led to the creation of Twilio’s Customer Engagement Platform.
Setting the stageTwo things here:
- Twilio isn’t only about CPaaS anymore
- Twilio focuses on communications of business with customers. They aren’t after the UCaaS market in any way
If you look at the communications market diagram above which I like using, then Twilio encompasses two of the three domains. The difference now is that it is vying towards the CRM part with its new story of a customer engagement platform.
The pillars of Twilio’s Customer Engagement Platform?
From here on, the keynote was focused on showcasing everything revolving around customer experience with trust, scale, reliability and compliance as the main themes.
FUDing the enterpriseTo hammer the message through, Twilio decided to harness the “digital giants”. In its mind, these are Amazon, Google, Netflix and Facebook. An odd choice, as Apple and Microsoft would be “gianter” than Netflix…
The reason behind this, is that these companies make the best use of customer data to improve its engagement with its customers, providing a singular, cohesive view of them.
Logic states that these digital giants have grown with the pandemic because they understand their customers better, and other vendors need to follow suit or be gobbled up by these digital giants.
Now that we want to be like them, we need to have the technology to do that. Amazon didn’t buy its CRM from anyone, it built it. It fed it with the data needed. And so do you dear vendor – you can’t rely on an existing CRM – you will need to build it. And just accidentally, Twilio Flex is what you need to build it (wink wink ).
Oh, but it isn’t Twilio Flex. It is actually Twilio Flex + Segment + machine learning.
To hammer that in, Jeff made sure you know that you don’t want the digital giants as your partners when it comes to your customers: Amazon taking a cut of each purchase,the Apple tax, Facebook and Google auctioning user attention via ads. You dear vendor, need and want to own your customer relationship – directly:
Now that we’re all warmed up, it was time to share and explain what Twilio Customer Engagement Platform really is.
The Twilio Customer Engagement Platform Twilio’s new Marketecture: Twilio Customer Engagement PlatformTwilio’s new Marketecture: Twilio Customer Engagement Platform
Jeff went through the platform’s components, which sits well with its current set of product offerings and acquisitions.
1. ChannelsChannels are the basic Twilio building blocks. That’s roughly the CPaaS part of Twilio:
The purpose is to be where the customer is.
Messaging and Voice is what Twilio is focused on. Ads were not mentioned anywhere else. Email is the SendGrid acquisition. And Video… well… that’s almost the only place it appeared during the keynote (more on video later).
2. Engagement AppsThese are the higher level programmable applications that Twilio is offering:
- Twilio Flex for support (announced 3 years ago at Twilio Signal)
- Twilio Frontline for sales (announced a year ago at Twilio Signal, no new announcement around it in the keynote)
- Twilio Engage for marketers (announced later in the keynote)
- Custom apps are the ones you build yourself on top of Twilio’s CPaaS offering (their Channels)
Segment…
This is why Twilio acquired Segment a year ago, and this is where it is taking Segment next.
The reason behind acquiring Segment was to pivot towards customer engagement and provide a larger offering to larger enterprises.
As Jeff said it, this is about engaging customers in real time at scale – that’s the focus of Segment.
From here, the keynote went to specific product announcements.
Twilio Signal 2021 keynote announcementsDuring the keynote, several official announcements were made. There were others that didn’t make it into the keynote itself, which goes to show where the main focus is.
Here are the things announced in the keynote:
- Regional Twilio – running the Twilio stack and connecting to it over different geographical regions
- Twilio MessagingX – a rebranding of its SMS and omni-channel offering
- TrustHub – managing compliant phone numbers
- Google Business Messaging – support for Google Business Messaging
- Content API – new API for managing messages across channels
- Twilio IVR Now – helping contact centers migrate from on prem IVRs to the cloud
- Twilio Intelligence – a new business process automation platform for the contact center
- Twilio Flex
- Twilio Flex ONE – single API for multiple channels in Flex
- Twilio Flextensions – marketplace for partner extensions and implementations for Flex
- Segment
- Twilio Engage – marketing cloud engagement app for marketers
Jeff introduced this first and explained that this was their biggest architectural change.
Twilio switched from a single US based data center to enabling running the Twilio stack from multiple regions. A customer can potentially choose where he wants to connect to Twilio and where he wants his data to reside.
The main difference is lower latency on API calls if sent to the same region, but mainly the ability to choose where to run and store the data.
The actual deployment of this is going to happen in stages with a growing number of locations as well as products enabled. This will start with two new regions – Australia and Ireland, to cover Europe and Asia by year end for Twilio Voice; while Twilio Segment can store data in Europe.
The main reason for this is the growing need to support regional data storage to meet regulation in different countries and the need to entice larger enterprises to use Twilio.
This was announced before the explanation of the Customer Engagement Platform, but I decided to place it here, as part of the announcements of the keynote.
Twilio MessagingXThe first announcement after introducing Twilio Customer Engagement Platform was Twilio MessagingX – the Channels layer in the new marketecture. This is also where the heart of the Twilio CPaaS solution lies.
It started nice. Soumya Srinagesh, Twilio’s VP Messaging Exchange, shared her big number:
Somehow, it differed from Jeff’s by 28B. I am sure there’s a good explanation, though either way, 100B is a large enough number.
SMS centered, but evolvingFor Twilio, messages are still SMS. It wasn’t said out loud, but it was hinted strongly enough throughout the session based on the announcement and in the analysts briefing for Twilio MessagingX:
During the analyst briefings of Twilio Signal 2021 the above slide was shared. I like it because it says a lot about how Twilio sees things in the messaging space. I also like it because of the way things are arranged.
Here are my immediate insights from it:
- SMS is the biggest channel by far. Everything else is just noise
- Whatsapp comes second, and then Facebook Messenger
- RCS is puny (it is still dead before arrival)
- All of the above is true because Twilio deals with business to consumer communications
- Until now it was mostly business to consumer
- Whereas the future is in conversations where consumers initiate more of it, where social networks and Apple/Google are more important
- It also doesn’t take into account communications that aren’t business to customers. Business to business and just person to person, which may happen in other channels
So what exactly is Twilio MessagingX?
It looks at messaging not from the API building block level, but rather from 3 different perspectives, each with its own set of focus and investments: Trust, Quality and Choice.
To be clear, all CPaaS vendors strive to do that. Twilio is one of the few that are big enough with economies of scale to really deliver it, and do so with programmability in mind in all of the possible layers.
TrustTo handle trust, mainly deliverability and compliance, Twilio announced TrustHub.
TrustHub is all about compliant phone numbers (did we say SMS?)
It isn’t as if other CPaaS vendors don’t offer compliant phone numbers. TrustHub does that by enabling access to it via APIs as well, making it… programmable? More flexible?
The intent at the end of the day here is to have messages pass unfiltered and not get them to be blocked by carriers. Especially now, when our phone’s spam folders for SMS and voice are full of such numbers and messages.
This initiative is starting with the US market and will expand elsewhere.
QualityThis is about deliverability by selecting which carriers to use to route messages, and figuring out bad connections. Twilio does that proactively (other CPaaS vendors do or say they do as well).
Not much else was said about it during the keynote, but this is where many of its acquisitions and investments in communication providers such as Syniverse earlier this year come to play.
This is a topic for a separate future analysis though.
ChoiceChoice is omni-channel. The ability to send messages to users on the channels they prefer.
There were two announcements around choice that were made:
1. Google Business MessagesTwilio already had SMS, Facebook Messenger and Whatsapp. Now they added support for Google Business Messages – the ability of customers to start a conversation with a business directly from a Google search result or a map listing.
Interestingly, Twilio still has no Apple Business Chat support. Probably because Apple doesn’t want to deal with generic CPaaS vendors just yet.
2. Content APITo manage and handle the fact that each messaging channel has slightly different rules you need to deal with, the new Twilio Content API is there to allow writing a message once and delivering it on whatever channel, with Twilio taking the headache of matching the message you want to send to how each channel likes that message.
As messages become more complex, requiring the user to take actions for example, such an API becomes a nice add-on.
For the most part, it feels like a utility that reduces a lot of the headache of a developer.
Twilio Voice and IVR NowThis was the first time voice was discussed. It was preceded by this nice number:
We had 25B calls, now with 36B voice minutes. If both relate to voice, then that’s 1:26 minutes per call on average. Transactional is the main focus of Twilio.
Not much more has been said or announced about Twilio Voice directly. The only thing was IVR Now, with about a minute spent on explaining it:
IVR Now seems to be a program that is designed to assist enterprises to migrate their VoiceXML from on premise IVRs to Twilio’s IVR. If I had to guess, this is about offering professional services either by Twilio directly or via partners.
The reason for sharing this during the keynote was to get enterprises listening in to talk to Twilio about it – there still isn’t anything on Twilio’s website about this program…
Other than that, it felt out of touch with the rest of the keynote.
Twilio IntelligenceAl Cook, VP & GM, Artificial Intelligence was the one introducing Twilio Intelligence. Al was the one leading and announcing Twilio Flex a few years ago, and this in a way is an extension of it.
The premise of Twilio Intelligence is the need to get from voice to data to meaning.
Twilio Autopilot was released to beta in 2018 and GA’d during Twilio Signal 2019. Interestingly, this is a platform and not a product (which means it probably is still Twilio Autopilot).
What is included?
- Driven by conversations
- Your own switch transcription engine and language understanding capability
- The transcription engine itself was built by Twilio, not using third parties
- This reduces the price points for Twilio and increases their ability to deliver a specialized solution
- The data used to train the engine was labeled with type of data and calls that Twilio sees with its customers
- This leads to accuracy higher than 90% (based on Al’s explanation)
- The Twilio transcription engine is included in the Intelligence platform but can also be used as a standalone API
- Accents were mentioned but not languages, so this is probably English only at this point in time
- The intelligence part comes with language operators which can be trained by the vendors themselves
A view of the language operators of Twilio Intelligence as implemented as part of Twilio Flex
Here’s what it means that Twilio Intelligence is a platform:
- This isn’t a specific product, but a mix of multiple Twilio products and capabilities
- Twilio voice recordings will now offer transcriptions, most probably with diarization based on the channels in the call
- Segment stores the data
- Twilio Studio is used to manage and automate decision trees based on the language operators
- Twilio Autopilot or something newer/different is used to sift through that data to get to the understanding part of it
- Twilio Flex holds all that glue together with the application level implementation of it all
The demo was quite interesting, so I decided to share the direct pointer to it in the keynote here, as that’s easier than explaining it:
What I think:
- This is the holy grail of call centers
- Being able to understand conversations at scale
- Automate proactive actions
- Do things intelligently
It is hard work, and it will be interesting to see if Twilio nailed it this time around and what the next iteration of this will look like.
Where and when?
Now in limited private beta. A broader private beta in early 2022.
English only for now. Voice based for now.
Twilio FlexTwilio Flex launched 3 years ago. At the time, it was questioned if this would be successful or not. To some extent, it still is. The interesting thing is that the same was said about Amazon Connect, which took about 3 years to mature enough to show its size in the market.
Sateja Parulekar, Head of Contact Center Solutions at Twilio made it a point to explain that:
- Large contact centers are already using Flex
- Flex is the fastest growing product at Twilio (though no specific numbers around size were given, besides the 0.5B interactions at the beginning)
{kind=link}
There were new announcements around Flex, mainly Flex ONE and Flextensions.
Flex ONE{kind=link}
Flex ONE is about adding new channels to the Flex contact center with a single API. That includes today voice, messaging (including Whatsapp), chat and email.
The end result is one page holding all conversations across all channels with the customer.
FlextensionsFlextensions are pre-build extensions to Twilio Flex. To me it sounded much like Zoom Apps or application directories of other enterprise tools.
This is geared on top of the partnerships that Twilio has been working hard on and explained in last year’s Signal 2020 when they discussed the Twilio Flex ecosystem. It is the right move for the Flex platform.
From a product perspective, the future of Flex lies in its integration with Segment. This is where Twilio Intelligence is most focused on, as we’ve seen in its introduction and demo.
SegmentPeter Reinhardt, GM of Twilio Segment came to explain two things:
- What is Segment and why Twilio acquired it
- Announce Twilio Engage
Segment is about collecting customer data from multiple sources and making it available as the single source of truth to wherever the business needs that data – all in real time.
Businesses store data about customers in many different places. With the migration towards cloud and SaaS, the number of these places is growing fast. I know… my own small business to run this website and my courses have their own share of SaaS vendors that I am using, all cobbled up with half-made integration and knit together with this masking tape called Zapier. It works. For my single person small business. Somewhat (I have tons of things I’d love to have better integrated, but don’t have the time or inclination to do – not enough ROI in it).
For real businesses, not like mine, the problem is a lot bigger and a lot more important to solve. Especially if… you want to be like the digital giants Jeff talked about at the beginning of the keynote and Peter made sure you remembered.
But back to the why:
- Businesses need a glue for their customer data. And Segment is a nice glue. A super glue
- Twilio does communications APIs. And is going after businesses, especially where businesses need to communicate with customers
- So the data used to decide if and how to communicate resides in Segment, or gets pushed to Segment from Twilio
- A win win if you could integrate these two together
And we’ve already seen glimpses of it with Twilio Intelligence earlier on.
I think Segment was the most interesting acquisition of Twilio so far. It isn’t only closing a gap on something they don’t have or need. It isn’t even going after a close adjacency. It is about being able to double down on customer engagement… and building a platform for it.
Which is exactly where Jeff started and where the keynote ends.
Twilio EngageTwilio Engage was the last announcement. This is the new engagement app that Twilio decided to launch. Flex is for support, Frontline is for sales and Engage is for marketers. This is the marketing cloud offering of Twilio, built on top of Segment.
It is available in pilot now and as GA in Q1 next year.
Not much else was explained or shared about this and the demo was mostly a concept of what can be done with it. Next year’s Signal event will probably show the flashy UI Peter said was less important than the data
Announcements that didn’t make it into the keynoteVideo. IoT. Frontline. Sendgrid.
Probably a few others that I missed.
I’d like to discuss 2 of these announcements here in brief.
Twilio Video InsightsVideo isn’t (and was never) top of mind for Twilio. They have it supported, but somehow it feels like a second class citizen most of the time: Twilio WebRTC Go was announced in Signal 2020 to give a semblance of progress with video. It is a free peer-to-peer video service from Twilio that is limited in scale. It got some increased capacity this year especially for Signal 2021. Nothing to write home about (I already discussed these free WebRTC video APIs at length recently.
What was announced was Twilio Video Insights and Twilio Video, both very different from each other.
Twilio Video Insights collects WebRTC and other statistics off of your calls done over Twilio Programmable Video, to create a dashboard view of media quality.
This is similar to what we do at testRTC with our watchRTC product.
A demo was shown in one of the sessions of Twilio Signal.
For me this validates our own watchRTC product, as Twilio saw the need to offer that out of the bex as part of its service. That said, if you need something like this (for Twilio, another CPaaS vendor or your own infrastructure), then come check for yourself which tool is most suitable for your needs.
Twilio LiveTwilio Live was announced a bit prior to Signal 2021. Probably in order to give center stage to Twilio Customer Engagement Platform where Live (or video for that matter) play a marginal role if any.
Here’s what I learned about Twilio Live during Signal 2021:
- Twilio Live offers “interactive” audio and video
- “Interactive” because there’s a 2 seconds latency end-to-end
- It isn’t WebRTC on the viewer’s end, which can probably be blamed for that 2 seconds of latency
- The problem with this is that today’s CDN streaming solutions that can go down to 5-10 seconds, and with further optimizations of their existing technology stacks down to 2 (using LLHLS for example)
- Their competition from WebRTC streaming vendors is that these vendors support subsecond latencies, usually at the 500 milliseconds mark
- CDNs are probably cheaper. WebRTC streaming vendors will probably be on par with Twilio’s pricing
- Main reason for selecting Twilio here is if you’re using the Twilio stack elsewhere as well, but it might not be enough if what you are looking for is real interactivity
- Yes, 2 seconds delay is great for most use cases, but not for all of them
- It reaches millions of users on a single stream
- I’d estimate that Twilio Live runs like a traditional CDN streaming service
- It sends data over TCP (using HTTPS or a secure Websocket), so there’s no packet loss and there’s buffering added to deal with potential retransmissions
- It probably also does ABR (adaptive bitrate), to deal with different bandwidth availability of different users
- Twilio Programmable Video Group Room is used as the source of the content
- Which means the broadcasters are using WebRTC
- Since a single outgoing stream is sent towards Twilio Live, this gets mixed and “recorded” and then sent to the audience. All this is probably done by a headless chromium instance in the cloud somewhere
- The fact that the content is mixed means that all viewers can only see the exact same layout. Less flexible, especially for the interactive type of use cases with several broadcasters
It is an interesting route that Twilio took for its broadcasting service. I am not sure how well it can compete with other CPaaS vendors who are clocking 100s of users or more per single WebRTC session. And it is hard to see this as an alternative for those using CDN streaming services already.
What will be interesting to see is how vendors accept this product and its position in the market – will this be good enough or even perfect for certain customers that can’t find the right solution for their broadcasting needs elsewhere.
What Twilio isn’tAfter writing down this longform article and analysis of Twilio Signal 2021, I think the most important part is what wasn’t said. And that’s what Twilio isn’t.
I long suggested and thought that CPaaS, CCaaS and UCaaS are going to merge as the lines between them are blurring. Vendors in each of these segments are vying towards the others through new product announcements and acquisitions.
Twilio went after CCaaS with Flex. It only made sense it would move into UCaaS at some point, being a comfortable adjacency in communications.
But it didn’t.
It went after customer engagement. Acquired Segment and doubled down in this route – making a splashing announcement of it at this Signal event and keynote.
Twilio is all about businesses communicating with customers.
Twilio is a lot less about people collaborating with each other in a business. Why? Because that’s where the focus of UCaaS is, and a lot of that focus relies on a slightly different set of requirements and roadmap.
This is also why video is getting less attention by Twilio for example.
What’s next for Twilio?I don’t really know.
This can be seen as a pivot, but also as the next step in Twilio’s evolution.
Twilio is surprising with the way it handles itself in the market, at least for me.
If I had to bet, I’d say that the next 2-3 years are going to be more of the same. Twilio will work on its current set of engagement applications, pouring data from the Segment CDP into it, and fitting its solutions for sales, support and marketing. Obviously, developers are still an important part of all of this.
I wouldn’t expect Twilio to go into additional adjacencies in the API domain or to go after unified communication related use cases either. At least not now. They have their hands full going up market and out of their comfort zone of pure communications.
The post Twilio Signal 2021: A Pivot from CPaaS to Customer Engagement Platform appeared first on BlogGeek.me.
A year of WebRTC Insights
WebRTC insights is turning out to be fun to create and super useful to our clients, looking to navigate the world of WebRTC.
Philipp Hancke and myself started this new thing called WebRTC Insights a year ago. We work well together, so we simply searched what we can do other than the WebRTC codelab, which was and still is a fun project.
WebRTC Insights is meant to help vendors sift through the technical (and non-technical) information that is out there and ever changing around WebRTC. Anything from bugs found, important changes in the WebRTC implementation to security issues raised and many other topics.
The idea? If you are a developer who uses WebRTC on a daily basis and relies on it, we can reduce the time you spend on finding what can bite you in the back when you weren’t looking. And we can definitely reduce the risk of that happening.
A year has gone by. The service evolved through this time, as we added more insights into it. Time to look at what we’ve done
WebRTC Insights by the numbersWe started small. The first WebRTC Insights issue looked at 6 issues, 7 PSAs and 2 market insights. 4 pages in total. Now we’re at 15-20 issues on average (twice as much when a Safari release happened) and 10 pages (or more).
In numbers, over the year this turned out to be:
26 Insights issues, 331 issues & bugs, 120 PSAs, 17 security vulnerabilities, 74 market insights and 185 pages. Phew…
BugsIn the past decade we have had more than 13,000 issues filed against libwebrtc, Google’s implementation of WebRTC that we all use in Chrome (and all other browsers in one way or another), with close to 5,000 of them external bug reports. In addition to that close to 2,000 external chromium bugs related to WebRTC.
WebRTC is a complex piece of software and staying on top of it requires quite some effort. While the development activity on WebRTC is much lower these days (at a third of the peak change rate back in 2017) there is still a surprising amount of issues we have to look at.
WebRTC Insights started from conversations about WebRTC issues and the challenges they bring between us. We have long looked at and discussed bugs, but this happened over chat and we never wrote it up. Nowadays we write up a summary, our thoughts and the potential impact each bug has. Quite often we learn something from it.
In the process we actually created an annotated list of issues that we can then refer to when we encounter new issues. So when Tsahi complained about an increase in video jitter statistics recently, Philipp just pointed him to the issue where we discussed this topic (you see, Tsahi’s memory isn’t what it used to be).
Mailing lists and PSAs“Public Service Announcements” or PSAs are a way for the WebRTC team (and Philipp) to communicate breaking changes in WebRTC. They range from changes to the C++ APIs to the plan-b deprecation and typically require action from developers using WebRTC in their applications.
We also list WebRTC-related Intent-to-ship from the Chromium process. This is a mandatory step in the process to launch WebRTC features that require Javascript API changes. In the last year we have mostly seen changes related to screen sharing which then turned into features of Google Meet – yet were available to other users of the platform as well.
Last but not least we do monitor the W3C working group and what happens there as it has a long term impact on where WebRTC is going.
The crazy profession syndrome: WebRTC trials in ChromeWebRTC uses field trials in Chrome to roll out changes that have some technical risk. We identify them which gives us insights into what might be a possible root cause for issues that are hard to reproduce locally. The best example for this recently was this report by Facebook where an experimental change to reduce the noise during opus dtx caused a large AV desync issue. We had been tracking the experiment for a couple of weeks at that point.
Security patches in WebRTCWe keep track of WebRTC related CVEs in Chrome (17 in the last twelve months), determine whether they only affect Chromium or when they affect native WebRTC and need to be cherry-picked into forks of the native library.
Where is the market headed?This part is the bird’s eye view that we offer. The rest of the insights are the low level details developers need. Here, we look at the bigger picture of what WebRTC is and the market forces around it.
We bump into tweets, posts, LinkedIn messages and other articles out there – and when we feel they are relevant and important to your work, we mention them. And explain where we see this trend headed and what you should be aware of.
The market insights are designed and handpicked for the clients we serve in WebRTC Insights.
We’re evolvingOver time, we’ve evolved the service.
Security and Chrome trials were added later on. We are now experimenting ourselves with short video explainers of each libwebrtc release (=once a month) and its implications to developers. We got some great feedback on it, so we’re likely to keep it as part of our format.
There are now also 3 different plans to the WebRTC Insights:
- Light – the biweekly insights email
- Premium – Light + monthly brainstorming session
- Exclusive – Premium + unlimited access to courses
Want to join us for the ride this coming year?
To learn more, check us out at WebRTC Insights
You can leave us a message there to get a sample copy of one of our latest insights issue
The post A year of WebRTC Insights appeared first on BlogGeek.me.
Managed WebRTC TURN: The need for speed
What the announcements of Subspace and Cloudflare on their Managed WebRTC TURN services mean for the industry.
In the past couple of months we’ve seen two new entrants to the managed WebRTC TURN business. After stagnation for many years, this small market niche is becoming interesting. REALLY interesting.
Table of contents- TURN and the WebRTC developer ecosystem
- Challenges of using open source coturn in production
- Managed WebRTC TURN – the early days
- Why use a managed WebRTC TURN service?
- Managed WebRTC TURN – the post-pandemic version
- Which managed WebRTC TURN service to use?
TURN servers are used in WebRTC in order to get your sessions connected if there’s no direct route available. I am not going to go into the technical part of it, but I’d say that without TURN servers, not all of your WebRTC sessions will get connected. You don’t need it for all sessions, but for some, you won’t be able to work without it. They are an essential component that has its own category in my WebRTC Developer Tools Landscape.
{kind=link}
At the end of the day, TURN servers act as intermediaries by relaying the media between two points.
Roughly speaking, you have 3 alternatives in how you can get these set up:
- Self host. You can install and host your own TURN servers and manage them on your own. In most cases, this will be by using the open source coturn server
- Managed. You can use a third party that runs its own TURN servers, giving you access to their servers, paying for the service. Don’t search for free TURN servers – if they exist, then they aren’t worth the money you aren’t paying for them
- Everything and the kitchen sink. You could just go with a WebRTC CPaaS vendor. These will give you everything you need, including TURN servers and service. An all in one deal
In this article, I will be ignoring the “everything and the kitchen sink” approach. Not because it is bad, but because if you’re just interested in a managed WebRTC TURN, then you probably want to control a bit more of your destination (more on that later).
Challenges of using open source coturn in productionLet’s start with the self hosting approach. The leading choice today is to take coturn, a popular open source TURN server, and deploy it on your own. There are one or two other alternatives, but this is by far the most common one.
The challenge though stems from the fact that for TURN the majority of the issues aren’t around integration or development but rather in configuration and maintenance. As such, it falls into the laps of ops, but requires knowledge and understanding of WebRTC.
The main culprit? The fact that you don’t need TURN for each and every session – and that there are 3 different TURN transport protocols, offering a progressive fallback mechanism.
What does that mean?
You install and configure your TURN server. But how do you test that all went well? Just conducting a WebRTC session will not tell you that. If the session succeeded, is it because it didn’t need TURN or because it used your TURN server properly? And if it did use it properly, was that on all 3 different transport protocols?
Configuring TURN is a headache:
- Testing TURN configuration it isn’t straightforward
- Scaling TURN horizontally may seem simple, but it has its own set of challenges
- Geolocating TURN servers properly is tough and tricky when you’re small
- Securing your TURN servers from abuse isn’t hard, but another necessary task. So is monitoring it
- And then there’s the hacking angle to it, as Slack found out in 2018
In the early days of WebRTC, developers had two main alternatives:
- DIY – building everything on their own, including the installation and configuration of their TURN servers
- CPaaS – “outsourcing” all of the WebRTC infrastructure components including their TURN servers to a third party vendor who specializes in it
You either knew what you were doing or didn’t want to know what you were doing.
The initial indication for managed WebRTC TURN service came from two vendors. It started with Xirsys and continued with Twilio.
XirsysXirsys was the first vendor to offer a managed WebRTC TURN service commercially. It was limited to a data center or two when they started, but grew over time.
Today, the Xirsys Cloud service spans 7 regional data centers.
TwilioTwilio is the most widely known CPaaS vendor out there. It is playing the best of suite game, with its large and growing portfolio of services. One of these products is their Twilio Global Network Traversal Service, a half-hidden product that enables you to leverage their TURN servers for your application without using their other CPaaS and WebRTC products.
At the time of writing, Twilio runs its media over 9 different regions, all on AWS.
Why use a managed WebRTC TURN service?I guess it is a matter of experience and expertise. Do you really want to deal with questions such as how do you decide which TURN server to connect a user to? How to deal with WebRTC TURN geolocation?
A managed WebRTC TURN service eventually targets the exact pain points and challenges that setting up your own TURN servers pose:
- Someone else takes care of properly configuring the TURN servers (assuming they know what they are doing)
- They take care of scaling this for you, so you don’t need to deal with increases in traffic, at least not on the TURN servers
- You get someone else to decide on geolocation (and do it better than you can for the most part)
- Inherently, managed WebRTC TURN services secure their service from abuse, so that’s also a given – oh – and they’ll provide you with a nice usage dashboard as well
The best thing about managed WebRTC TURN services?
There’s no vendor lock-in.
Switching from one managed WebRTC TURN service to another or to your own self installed servers is a breeze – just change the iceServers configuration on your peer connections in WebRTC and you’re done. Theoretically, that’s a single line of code change.
It is also why I suggest anyone who is building their own WebRTC application to start by using a managed WebRTC TURN service – they can always switch to their own, and the cost of switching next year will be the same as just building it today. And as the lazy person that I am, I will always postpone to tomorrow something that I don’t have to do today.
Managed WebRTC TURN – the post-pandemic versionThen came the pandemic, with its lockdowns, quarantine and the rise in use of WebRTC and any other remote communications technology.
The market stayed roughly the same for managed WebRTC TURN servers, or at least it did until 2021. What happened is that we now have 2 more vendors in this domain: Subspace and Cloudflare. And they are different: they are bigger in the physical footprint they have and they make use of Anycast – an IP addressing and routing scheme used to connect a large set of globally spread servers via a single IP address. This type of a solution also makes things a lot simpler to whitelist when needed.
Subspace GlobalTURNSubspace offers better connectivity than the open internet. They do that by optimizing the routes your packets go through. What you do is send your packets through their network, which will then figure out the best route.
In 2021, they decided to expand what they are doing to WebRTC as well, offering their GlobalTURN service. With around 100 cities and an Anycast addressing scheme, they offer a global footprint.
For Subspace, this isn’t the first VoIP related product they offer, but it is the first WebRTC related one. Would they move towards hosting media servers as well? I think it is an unlikely path for them.
Cloudflare WebRTC ComponentsCloudflare announced their own deployment of a managed WebRTC TURN service called WebRTC Components. Besides it being a TURN service, there’s not much to go by yet.
What we do know is that it relies on Cloudflare’s anycast network spanning 250+ cities.
For Cloudflare, this is the first WebRTC related offering, which was announced alongside a slew of other capabilities, targeted at cloud vendors (their R2 storage which directly competes with AWS S3 for example). There’s a good overview of the disruption path Cloudflare is taking. The WebRTC addition to it is an interesting choice.
Interestingly, I debated the potential of using Cloudflare’s Workers as a TURN service enabler when it was announced. Seems like they decided to build it on their own
Which managed WebRTC TURN service to use?That should be the question you should ask yourself.
It isn’t about whether you should use a managed WebRTC TURN service or deploy your own – it should be which managed WebRTC TURN service to select. Why? Because this is super simple to adopt and replace with zero vendor lock-in.
Pricing is important, but also global footprint, latency and quality. Then there are things like actually doing its job – the percentage of successful connections you get with it.
It will be interesting to see if and how Xirsys and Twilio address the threat from the newcomers to this market niche. For Xirsys this should be more worrying than it is for Twilio, as that’s one of their core products, whereas for Twilio it is a small part of what they offer to their customers.
Who would have thought that in 2021 we will see competition and innovation coming to the managed WebRTC TURN service?
The post Managed WebRTC TURN: The need for speed appeared first on BlogGeek.me.
How does WebRTC End-to-End Encryption work? Matrix.org example (Dave Baker)
One of WebRTC’s great features is its mandated strong encryption. Encryption mechanisms are built-in, meaning developers don’t (often) need to deal with the details. However, these easy, built-in encryption mechanisms assume you have: 1) media is communicated peer-to-peer and 2) a secure signaling channel setup. Most group-calling services make use of a media server device, […]
The post How does WebRTC End-to-End Encryption work? Matrix.org example (Dave Baker) appeared first on webrtcHacks.
Apple’s not so private relay fails with WebRTC
Apple released iOS 15 with iCloud Private Relay broken for WebRTC - it still divulges your IP address. This post walks through why and how the WebRTC API's use your IP address information and how you can check what IP addresses are gathered.
The post Apple’s not so private relay fails with WebRTC appeared first on webrtcHacks.
Free WebRTC Video API in CPaaS. Is it worth it?
Are free minutes and accounts in WebRTC video API worth the trouble? I think not. Don’t choose your CPaaS vendor based on their “free” tier.
I am finalizing my 10th edition of Choosing a WebRTC API report these days. In the past year I’ve heard from a few vendors and developers questions about the free tiers in this space. So I took the time as part of this edition, to sit down and analyze the price plans of the various vendors in the market and create another article as part of the report (one that is available through the membership site for those who purchase the report).
In this article, I want to shine a light on one aspect of price plans in WebRTC APIs which is the free tier.
Let’s dive into things, shall we?
Table of contents- Free tier is optional
- Free depends on the plan
- 10,000 free WebRTC minutes
- WebRTC video free tier? Money Time
- How do you choose a WebRTC CPaaS vendor?
14 out of 24 vendors I looked at practice per minute pricing. Sometimes, they have multiple price strategies, but per minute pricing is the most common – especially on the bigger more widely known vendors.
Out of the 14 vendors, 5 offer free tiers in one way or another. And 2 offer credits – Amazon Chime SDK and Microsoft Azure Communication Services – these two offer IaaS cloud credits to startups as general practice and their CPaaS/WebRTC offering wraps into these as well (I’ve written about cloud giant effect on the CPaaS market last year).
Not all WebRTC API vendors offer a free tier
Free tiers seem to be almost “random” in who offers them and who doesn’t
Free depends on the planSome vendors have free plans that depend on different things.
For Twilio, for example, free minutes come only with their Twilio Video WebRTC Go service, which… amounts to ~$10/month, and offers a limited peer-to-peer experience.
With some vendors, the free plan is actually a limited free evaluation for 1-4 months in timeframe.
That said, the most popular alternative seems to be free minutes on a paid plan. You give your credit card, and will only be charged if you pass a number of minutes on a given month. More on that – in the next section.
Free monthly minutes depend on the plan/feature set you choose/use
It might also be dependent on what you pay (did we say free plan?)
10,000 free WebRTC minutesMost vendors that give free minutes, are giving 10,000 free minutes per month.
Some give less. A few give more. The highest is 30,000 minutes per month.
If your service offers group calls of 10 participants for 30 minutes each time on average, then a single group call will take 300 minutes. That means ~33 such calls a month are free. Or a bit over a call a day.
This isn’t much. Not even for a small vendor just starting out. To be clear – this isn’t to say that 10,000 free minutes isn’t nice. Just that it won’t get you far.
The number of free minutes offered may seem a lot, but calculated for a use case they aren’t that many
Many small vendors see upwards of a million video minutes a month, so this amount to 1% of less of their total monthly minutes. Negligible in the long run
WebRTC video free tier? Money TimeMinutes are nice, but how about money? How much money do you actually save with these free minutes?
I did the math. The numbers range between $30-$90 per month. Less than $1,000 per year.
If you are building a business and making your long term plans on the CPaaS vendor to use based on a potential discount of $1,000 a year then you’re doing it wrong.
Why aren’t CPaaS vendors offering higher free plans? Because they have costs they need to cover. Assuming a 10% cost over that price point, then 1,000 “free” accounts will cost them up to $100,000 a year to maintain. And that doesn’t include the support costs which are higher.
CPaaS vendors would like to have startups sample and use their service, but they also need to operate as a business and make money. Giving more minutes than they do today probably isn’t going to accomplish more paying customers – it will just bring in more free riders that will also leach on their soul and support resources.
Free WebRTC video CPaaS plans worth less than $100/month
When making your decision on choosing a vendor, ignore that plan in your own business plan
As a CPaaS vendor, decide if you want such a free tier and what type of customers it is going to attract
How do you choose a WebRTC CPaaS vendor?The answer to this question is definitely NOT through their free tiers or minutes…
To some extent, the decision is made these days via pricing. It is why I’ve written in this round of my report to include a special article dedicated to pricing of WebRTC calls in CPaaS services. This includes the leading metrics these platforms use for their price plans as well as price ranges for each vendor. For this analysis, I’ve also added Zoom Video SDK as another reference point for pricing.
The report itself introduces a new CPaaS vendor and removes another vendor. It also sports a new features set structure, one that is geared towards the changes in requirements made due to the pandemic.
This report is used today by:
- CPaaS vendors themselves, who wish to understand their competitive landscape
- Enterprises and startups who need to pick and choose a CPaaS vendor to work with
- Companies who wish to start a CPaaS business or compete through an adjacency type solution
- Investment first looking to understand the market and… make an investment decision
This month, until the report gets officially published, there’s a $500 discount. You can use coupon code API2021LAUNCH when you purchase the report.
Learn more about my reportThe post Free WebRTC Video API in CPaaS. Is it worth it? appeared first on BlogGeek.me.
How to hire WebRTC developers for your job
Hiring WebRTC developers? Here are some things you need to know and consider, since finding WebRTC experts for a job is challenging.
You’re growing. Obviously. And you have this huge, important, strategic, one of a kind, critical project. And it requires WebRTC. Only thing missing is developers. Or should I say skilled WebRTC developers.
How do you go about finding, hiring and retaining WebRTC developers?
I wrote a short post on LinkedIn the other day about this:
Typical conversation on #WebRTC recruitment
You: “Do you know any developer who can help us with WebRTC?”
Me: “No. Those I know either have a day job they love are are freelancers not looking for work (and almost always fully booked)”
You: “If you learn of a developer available let me know“
Me [Thinking ]: “Join the club at the end of that waiting list…”
Finding developers that know WebRTC is really hard. Seriously.
There’s a lot more demand than supply in this one, and the market is tiny compared to other technologies you need to deal with.
If you’re looking for WebRTC developers you can either:
poach someone from another vendor who does WebRTC. Tricky and expensive
find someone with the inclination and train him on WebRTC
If you’re on that second track of training, I can help you.
This brought with it a request to write this in longform so Philipp Hancke will have a place to refer recruiters to…
yes. Tsahi, please write a blog post so I can have a canned response for recruiters
— Philipp Hancke (@HCornflower) August 5, 2021Philipp – this one’s for you
Table of contents- WebRTC developers: A supply problem
- The challenging skillsets of WebRTC
- Hiring WebRTC talent
- More than just WebRTC developers
- Can I help?
Oh – and if you are interested in history, this isn’t a new topic here. I wrote about finding WebRTC developers years ago…
WebRTC developers: A supply problemThe chart above shows a crude comparison between WebRTC usage and LinkedIn profiles. While the pandemic has shown a huge increase in WebRTC usage (=demand) the change in LinkedIn profiles has been relatively moderate (=supply).
Here’s the two separate charts showing each data point independently:
LinkedIn profiles showing “WebRTC” in them grew steadily from ~17,000 to 25,000 profiles (47% growth in total) whereas growth in WebRTC usage (calculated as calls to GetUserMedia in page loads) grew 0.05 to 0.22 (340% growth in total), peaking at almost 0.6 with the pandemic (that’s %1,100 growth).
We’ve got a supply problem with WebRTC. There’s a shortage of developers, architects, product managers, testers and support who are savvy enough with WebRTC. They are all hard to come by, and it is harder still to know what they really know about WebRTC – installing your own Jitsi server and playing with it is different than running it at scale or developing your own SFU media server from scratch.
With this in mind, you can safely assume that one of the most popular topics raised when people talk to me about WebRTC is hiring WebRTC developers – or more accurately, if I can recommend anyone specific.
The challenging skillsets of WebRTCWhy is it that it is hard to find WebRTC developers?
I think it starts from the diagram below:
WebRTC is multidisciplinary by its nature. It is located right between web and VoIP technologies:
- Web developers would find WebRTC challenging
- VoIP developers would think they know everything (but they don’t)
This means a developer who needs to handle WebRTC needs to have a good grasp of more than a single field of software development. And this isn’t easy to come by.
There’s one more reason though, and that’s the fact that WebRTC means different things to different people, and isn’t really focused on a single set of skills. Look at the short set of questions I’ve asked years ago about how much WebRTC developers are worth. The answers are mostly around “it depends”, where it depends on what tasks or job description that developer is filling up.
Here are the main areas today that you may need to find different profiles of WebRTC developers:
- Frontend
- Backend
- Mobile
- Telephony
In each domain, the skillset is slightly different and you will be hard pressed to find a superhero developer that meets all your requirements in all areas.
Hiring WebRTC talentWebRTC hiring is challenging. If you are looking for talented engineers who know a thing or two about WebRTC, then you are in for a world of pain. Finding them isn’t easy and hiring them is even harder.
Here are the different techniques I’ve seen vendors take when trying to find and hire WebRTC engineers.
WebRTC head-hunting and poachingYou can go head hunting for WebRTC talent. Bear in mind 3 things though:
- There aren’t a lot of WebRTC developers out there
- Most of them are in cushy jobs not looking to change places
- Many of them don’t even go on the open market when they need to look for their next gig. They go through “friends and family”, and since the market has so much pent up demand, this is usually where they will land
There are two approaches here. Let’s call them bottom up and top down.
Bottom up – you find the individual developers that fit the profile you are looking for, and then you reach out to them to see if they are bored enough to consider moving elsewhere
Top down – target a vendor in this space who you think peaked or someone who got acquired or just someone you think a bit vulnerable and attractive as an employer, and then figure out who are the developers there worth approaching to poach
Neither approach is easy. They are time consuming, frustrating and long.
Job boards and job listingsYou could use traditional job boards and job listing sites, place the job opening on your website, etc. What you’ll most probably get is going to be generalists with little domain knowledge and expertise in WebRTC. This means most applicants won’t have the WebRTC experience you seek.
The only other option here is to do an ad placement on WebRTC Weekly and/or webrtcHacks – many of the sponsors there use it for job listings, and you can try as well. The main advantage here is that the readership is quite relevant – developers working with WebRTC.
* Note that I operate WebRTC Weekly and affiliated with webrtcHacks
Hire from an adjacencyThis is something I suggest to many of my clients. Hire from an adjacency:
- Video streaming industry
- VoIP or traditional video conferencing
- Telephony
- Software networking
My favorite is probably finding companies that vanished, for example Polycom Israel. They had a large engineering team in Israel experienced in video conferencing. You can try to find developers who worked there 5-10 years ago and… moved on – often to other domains. And try to get them back. They won’t be experts in WebRTC, but they’ll know a lot about how to handle real time video. And that’s better than nothing.
The same is applicable elsewhere in the world and in other adjacencies.
When hiring from an adjacency though, you will need to be certain the candidate in question isn’t “in love” in how things are done today and have the willingness and the openness to learn and grow. WebRTC brings with it new paradigms and challenges and developers who have partial experience and knowledge from an adjacency need to be open to learn new concepts.
Nurture and grow in-house WebRTC expertiseWhen all else fails, you’ll need to grow someone in-house or train a new hire that is clueless about WebRTC to become that expert. Not an easy task, but certainly achievable.
WebRTC requires a certain inclination. There’s a need to wrap your head around asynchronous events and programming (lots of await and callbacks). There’s a need to understand codecs and lossy compression mechanisms (at least at the conceptual level). There’s perpetual optimization and fine tuning work that goes with it. Not everyone likes to work in such environments (I thrive in them).
Once you find that person, you will need to train him. Something that again can happen in one of 3 ways:
- Throw him into the water. He probably knows how to Google and find his way on the Internet. He will either sink or swim. I believe this involves too much time, risk and wasted effort
- Have someone train him. If you have WebRTC developers already, then adding a new one and training him can be done in-house. But that will take time from your developers in creation of materials, training and frustration – they might not even be good at training while being great developers
- Put him on a WebRTC training course. There are a few of these out there, so might as well have him enroll in one (or a few of them). I know for a fact that there is a good WebRTC training for developers out there probably because I author and maintain it…
I have only discussed developers so far, but the product life-cycle of WebRTC products involves more than just the engineers who need to understand WebRTC. There are a few more roles to think about:
- System Architects – they need to understand how different design decisions affect the end results, where the limits are, what architecture alternatives they have, etc.
- Product Managers – need to speak the language. Especially should be aware of what is or isn’t feasible with WebRTC. They need to understand the time and cost implications of the decisions they make
- Testers – if you’re going to test something that makes use of WebRTC, you better know what WebRTC is and what it is capable of…
- Support and Sales – people are going to ask technical questions. Be it because they got into a pickle and can’t connect or have bad quality. Or because they are buying and want to understand what’s in there
All of these roles need a solid understanding of WebRTC if it is part of the things you are offering in your company.
Can I help?Yap.
There are several things that I actively do here:
- Online training courses for developers (and other roles)
- Assistance in writing job listings
- Publish your job listings on WebRTC Weekly and/or webrtcHacks
- Screen candidates based on CVs
- Conduct technical job interviews to your potential candidates
- Offer coaching to the WebRTC experts you’re grooming
If you’re interested in learning more, feel free to contact me.
Oh – and don’t ask me if I know someone suitable. You’re likely not the first to ask me that this week.
The post How to hire WebRTC developers for your job appeared first on BlogGeek.me.
Dealing with HTMLMediaElements and srcObjects in WebRTC applications
Philipp Hancke discusses a how to properly release Media Element resources with WebRTC and a recent Chrome issue that apps to stop handling larger numbers of participants.
The post Dealing with HTMLMediaElements and srcObjects in WebRTC applications appeared first on webrtcHacks.
Tweaking WebRTC video quality: unpacking bitrate, resolution and frame rates
WebRTC video quality requires some tweaking to get done properly. Lets see what levels we have in the form of bitrate, resolution and frame rate available to us.
Real time video is tough. WebRTC might make things a bit easier, but there are things you still need to take care of. Especially if what you’re aiming for is to squeeze every possible ounce of WebRTC video quality for your application to improve the user’s experience.
This time, I want to cover what levers we have at our disposal that affect video quality – and how to use them properly.
Table of contents- What affects video quality in WebRTC?
- Device related
- The 3-legged stool of WebRTC video quality
- Follow the bitrate
- Making a choice between resolution and frame rate
- Time to learn WebRTC
Video plays a big role in communication these days. A video call/session/meeting is going to heavily rely on the video quality. Obviously…
But what is it then that affects the video quality? Lets try and group them into 3 main buckets: out of our control, service related and device related. This will enable us to focus on what we can control and where we should put our effort.
Out of our control From my workshop on WebRTC innovation and differentiationThere are things that are out of our control. We have the ability to affect them, but only a bit and only up to a point. To look at the extreme, if the user is sitting in Antarctica, inside an elevator, in the basement level somewhere, with no Internet connection and no cellular reception – in all likelihood, even if he complains that calls aren’t get connected – there’s nothing anyone will be able to do about it besides suggesting he moves himself closer to the Wifi access point.
The main two things we can’t really control? Bandwidth and the transport protocol that will be used.
We can’t control the user’s device and its capabilities either, but most of the time, people tend to understand this.
BandwidthBandwidth is how much data can we send or receive over the network. The higher this value is, the better.
The thing is, we have little to no control over it:
- The user might be far from his access point
- He may have poor reception
- Or a faulty cable
- There might be others using the same access point and flooding it with their own data
- Someone could have configured the firewall to throttle traffic
- …
None of this is in our control.
And while we can do minor things to improve this, such as positioning our servers as close as possible to the users, there’s not much else.
Our role with bandwidth is to as accurately as possible estimate it. WebRTC has mechanisms for bandwidth estimation. Why is this important? If we know how much bandwidth is available to us, we can try to make better use of it –
Over-estimating bandwidth means we might end up sending more than the network can handle, which in turn is going to cause congestion (=bad)
Under-estimating bandwidth means we will be sending out less data than we could have, which will end up reducing the media quality we could have provided to the users (=bad)
Transport protocolI’ve already voiced my opinion about using TCP for WebRTC media and why this isn’t a good idea.
The thing is, you don’t really control what gets selected. For the most part, this is how the distribution of your sessions is going to look like:
From my Advanced WebRTC Architecture Course- Most calls probably won’t need any TURN relay
- Most calls that need TURN relay, will do so over UDP
- The rest will likely do it over TCP
- And there’ll be those sessions that must have TLS
Why is that? Just because networks are configured differently. And you have no control over it.
You can and should make sure the chart looks somewhat like this one. 90% of the sessions done over TURN/TCP should definitely raise a few red flags for you.
But once you reach a distribution similar to the above, or once you know how to explain what you’re seeing when it comes to the distribution of sessions, then there’s not much else for you to optimize.
Service relatedService related are things that are within our control and are handled in our infrastructure usually.This is where differentiation based on how we decided to architect and deploy our backend will come into play.
BitrateWhile bandwidth isn’t something we can control, bitrate is. Where bandwidth is the upper limit of what the network can send or receive, bitrate is what we actually send and receive over the network.
We can’t send more than what the bandwidth allows, and we might not always want to send the maximum bitrate that we can either.
Our role here is to pick the bitrate that is most suitable for our needs. What does that mean to me?
- Estimate the bandwidth available as accurately as possible
- This estimate is the maximum bitrate we can use
- Make use of as much of that bitrate as possible, as long as that gives us a quality advantage
It is important to remember to understand that increasing bitrate doesn’t always increase quality. It can cause detrimental decreases in quality as well.
Here are a few examples:
- If the camera source we have is of VGA resolution (640×480), then there’s no need to send 2mbps over the network. 800kbps would suffice – more than that and we probably won’t see any difference in quality anyways
- The network might be able to carry 10mbps in the downlink, but receiving 10mbps in aggregate of incoming video data from 5 participants (2mbps each) will likely tax our CPU to the point of rendering it useless. In turn, this will actually cause frame drops and poor media quality
- Sending full HD video (1920×1080) and displaying it in a small frame on the screen because the content being shared in parallel is more important is wasteful. We are eating up precious network resources, decoder CPU and scaling down the image
There are a lot of other such cases as well.
So what do we do? I know, I am repeating myself, but this is critical –
- Estimate bandwidth available
- Decide our target bitrate to be lower or equal to the estimate
{kind=link}
Codecs affect media quality.
For voice, G.711 is bad, Opus is great. Lyra and Satin look promising as future alternatives/evolution.
With video, this is a lot more nuanced. You have a selection of VP8, VP9, H.264, HEVC and AV1.
Here are a few things to consider when selecting a video codec for your WebRTC application:
- VP8 and H.264 both work well and are widely known and used
- VP9 and HEVC give better quality than VP8 and H.264 on the same bitrate. All other things considered equal, and they never are
- AV1 gives better performance than all the other video codecs. But it is new and not widely supported or understood
- H.264 has more hardware acceleration available to it, but VP8 has temporal scalability which is useful
- Hardware acceleration is somewhat overrated at times. It might even cause headaches (with bugs on specific processors), but it is worth aiming for if there’s a real need
- For group sessions you’d want to use simulcast or SVC. These aren’t available with H.264 and probably not with HEVC either
- HEVC will leave you in an Apple only world
- VP9 isn’t widely used and the implementation of SVC that it has is still rather proprietary, so you’ll have some reverse engineering to do here
- AV1 is new as hell. And it eats lots of CPU. It has its place, but then again, this is going to be an adventure (at least in the coming year or two)
Choosing a video codec for your service isn’t a simple task. If you don’t know what you’re doing, just stick with VP8 or H.264. Experimenting with codecs is a great time waster unless you know your way with them.
Latency How you design your WebRTC infrastructure will affect the latencyWhile we don’t control where users are – we definitely control where our servers are located. Which means that we can place the servers closer to the users, which in turn can reduce the latency (among other things).
Here are some things to consider here:
- TURN servers should be placed as close as possible to users
- In large group calls, we must have media servers
- If we use a single server per meeting, then all users must connect directly to it
- But if we distribute the media servers used for a single meeting, then we can connect users to media servers closer to where they are
- The faster we get the user’s data off the public network, the more control we have over the routing of the packets between our own servers
- The “shorter” the route from he user to our server is, the better the quality will be
- Shorter might not be a geographic distance
- We factor in bandwidth, packet loss, jitter and latency as the metrics we measure to decide on “shortest”
Measure the latency of your sessions (through rtt). Try to reduce it for your users as much as possible. And assume this is an ongoing never-ending process
Here’s a session from Kranky Geek discussing latencies and media servers:
Looking at scale and serversThere’s a lot to be said about the infrastructure side in WebRTC. I tried to place these insights in an ebook that is relevant today more than ever – Best practices in scaling WebRTC deployments
Device relatedYou don’t get to choose the device your users are going to use to join their meetings. But you do control how your application is going to behave on these devices.
There are several things to keep in mind here that are going to improve the media quality for your users if done right on their device.
Available CPUThis should be your top priority. To understand how much CPU is being used on the user’s device and deciding when you’ve gone too far.
What happens when the device is “out of CPU”?
- The CPU will heat up. The fan will start to work busily and noisily on a PC. A mobile device would heat up. It will also start to have shorter battery life while at it. Interestingly, this is your smallest of worries here
- WebRTC won’t be able to encode or decode media frames, so it will start to skip them
- On the encoder side, this will mean a lower frame rate. Regrettable, but ok
- The decoder is where things will start to get messy:
- The decoder will drop frames and not try to decode them
- Since video frames are dependent on one another, this will mean the decoder won’t be able to continue to do what it does
- It will need a new I-frame and will ask for it
- That will lead to video freezes, rendering video useless
So what did we have here?
You end up with poor video quality and video freezes
The network gets more congested due to frequent requests for I-frames
Your device heats up and battery life suffers
Your role here is to monitor and make sure CPU use isn’t too high, and if it is, reduce it. Your best tool for reducing CPU use is by reducing the bitrates you’re either sending and/or receiving.
Sadly, monitoring the CPU directly is impossible in the browser itself and you’ll need to find out other means of figuring out the state of the CPU.
Content typeWith video, content and placement matter.
Let’s say you have 1,000kbps of “budget” to spend. That’s because the bandwidth estimator gives you that amount and you know/assume the CPU of both the sender and receiver(s) can handle that bitrate.
How do you spend that budget?
- You need to figure out the resolution you want to send. The higher the resolution the “better” the image will look
- How about increasing frame rate? Higher frame rate will give you smoother motion
- Or maybe just invest more bits on whatever it is you’re sending
WebRTC makes its own decisions. These are based on the bitrate available. It will automatically decide to increase or reduce resolution and frame rate to accommodate for what it feels is the best quality. You can even pass hints on your content type – do you value motion over sharpness or vice versa.
There are things that WebRTC doesn’t know on its own through:
- It knows what resolution you captured your content with (so it won’t try to send it at a higher resolution than that)
- But it has no clue what the viewers’ screen or window resolution is
- So it might send more than is needed, causing CPU and network losses on both ends of the session
- It isn’t aware if the content sent is important or less important, which can affect the decisions of how much to invest in bitrate to begin with
- Oh – and it makes its decisions on the device. If you have a media server that processes media, then all that goodness needs to happen in your media server and its own logic
It is going to be your job to figure out these things and place/remove certain restrictions of what you want from your video.
Optimizing large group callsThe bigger the meeting the more challenging and optimized your code will need to be in order to support it. WebRTC gives you a lot of powerful tools to scale a meeting, but it leaves a lot to you to figure out. This ebook will reveal these tools to you and enable you to increase your meeting sizes – Optimizing Group Video Calling in WebRTC
The 3-legged stool of WebRTC video qualityVideo quality in WebRTC is like a 3-legged stool. With all things considered equal, you can tweak the bitrate, frame rate and resolution. At least that’s what you have at your disposal dynamically in real-time when you are in the middle of a session and need to make a decision.
Bitrate can be seen as the most important leg of the stool (more on that below).
The other two, frame rate and resolution are quite dependent on one another. A change in one will immediately force a change in the other if we wish to keep the image quality. Increasing or decreasing the bitrate can cause a change in both frame rate and resolution.
Follow the bitrateI see a lot of developers start tweaking frame rates or resolutions. While this is admirable and even reasonable at times, it is the wrong starting point.
What you should be doing is follow the bitrate in WebRTC. Start by figuring out and truly understanding how much bitrate you have in your budget. Then decide how to allocate that bitrate based on your constraints:
- Don’t expect full HD quality for example if what you have is a budget of 300kbps in your bitrate – it isn’t doable
- If you have 800kbps you’ll need to decide where to invest them – in resolution or in frame rate
Always start with bitrate.
Then figure out the constraints you have on resolution and frame rate based on CPU, devices, screen resolution, content type, … and in general on the context of your session.
The rest (resolution and frame rate) should follow.
And in most cases, it will be preferable to “hint” WebRTC on the type of content you have and let WebRTC figure out what it should be doing. It is rather good at that, otherwise, what would be the point of using it in the first place?
Making a choice between resolution and frame rateOnce we have the bitrate nailed down – should you go for a higher resolution or a higher frame rate?
Here are a few guidelines for you to use:
- If your content is a slide deck or similar static content, you should aim for higher resolution at lower frame rate. If possible, go for VBR instead of the default CBR in WebRTC
- Assuming you’re in the talking-heads domain, a higher frame rate is the better selection. 30fps is what we’re aiming for, but if the bitrate is low, you will need to lower that as well. It is quite common to see services running at 15fps and still happy with the results
- Sharing generic video content from YouTube or similar? Assume frame rate is more important than resolution
- Showing 9 or more participants on the screen? Feel free to lower the frame rate to 15fps (or less). Also make sure you’re not receiving video at resolutions that are higher than what you’re displaying
- Interested in the sharpness of what is being shared? Aim for resolution and sacrifice on frame rate
I’ve had my fair share of discussions lately with vendors who were working with WebRTC but didn’t have enough of an understanding of WebRTC. Often the results aren’t satisfactory, falling short with what is considered good media quality these days. All because of wrong assumptions or bad optimizations that backfired.
If you are planning to use WebRTC or even using WebRTC, then you should get to know it better. Understand how it works and make sure you’re using it properly. You can achieve that by enrolling in my WebRTC training courses for developers.
Learn more about my WebRTC trainingThe post Tweaking WebRTC video quality: unpacking bitrate, resolution and frame rates appeared first on BlogGeek.me.
Identifying Shared Tabs using Capture Handle (Elad Alon)
Introduction to capture handle - a new Chrome Origin Trial that lets a WebRTC screen sharing application communicate with the tab it is capturing. Examples use case discussed include detecting self-capture, improving the use of collaboration apps that are screen shared, and optimizing stream parameters of the captured content.
The post Identifying Shared Tabs using Capture Handle (Elad Alon) appeared first on webrtcHacks.
Making Zoom’s Smart Gallery on the Web with MediaPipe and BreakoutBox
How to seperate multiple people in the same camera feed into their own unique video streams that can be individually transmitted Google's MediaPipe and the W3C's new MediaStreamTrack API
The post Making Zoom’s Smart Gallery on the Web with MediaPipe and BreakoutBox appeared first on webrtcHacks.
Why you should prefer UDP over TCP for your WebRTC sessions
When using WebRTC you should always strive to send media over UDP instead of TCP. at least if you care about media quality
Every once in a while I bump into a person (or a company) that for some unknown reason made a decision to use TCP for its WebRTC sessions. By that I mean prioritizing TURN/TCP or ICE-TCP connections over everything else – many times even barring or ignoring the existence of UDP. The ensuing conversation is usually long and arduous – and not always productive I am afraid.
So I decided to write this article, to explain why for the most part, WebRTC over UDP is far superior to WebRTC over TCP.
Table of contents- UDP and TCP
- TCP rules the web
- UDP rules VoIP
- WebRTC ICE: Preferences and best effort
- When is TCP (or TLS) good for WebRTC media?
- When will TCP break as a media transport for WebRTC?
- Time to learn WebRTC
Since the dawn of time the internet, we had UDP and TCP as the underlying transport protocols that carry data across the network. While there are other transports, these are by far the most common ones.
And they are different from one another in every way.
UDP is the minimal must that a transport protocol can offer (you can get lower than that, but what would be the point?).
With UDP you get the ability to send data packets from one point to another over the network. There are no guarantees whatsoever:
- Your data packets might get “lost” along the way
- They might get reordered
- Or duplicated
No guarantees. Did I mention that part?
With TCP you get the ability to send a stream of data from one point to another over a “connection”. And it comes with everything:
- Guaranteed delivery of the data
- The data is received in the exact order that it is sent
- No duplication or other such crap
That guaranteed delivery requires the concept of retransmissions – what gets lost along the way needs to be retransmitted. More on that fact later on.
We end up with two extremes of the same continuum. But we need to choose one or the other.
TCP rules the webReading this page? You’re doin’ that over HTTPS.
HTTPS runs over a TLS connection (I know, there’s HTTP/3 but bear with me here).
And TLS is just TCP with security.
And if you are using a WebSocket instead, then that’s also TCP (or TLS if it is a secure WebSocket).
No escaping that fact, at least not until HTTP/3 becomes common place (which is slightly different than running on top of TCP, but that’s for another article).
Up until WebRTC came to our lives, everything you did inside a web browser was based on TCP in one way or another.
UDP rules VoIPVoIP or Voice over IP or Video over IP or Real Time Communications (RTC) or… well… WebRTC – that takes place over UDP.
Why? Because this whole thing around guaranteed delivery isn’t good for the health of something that needs to be real time.
Let’s assume a latency of 50 milliseconds in each direction over the network, which is rather good. This translates to a round trip time of 100 milliseconds.
If a packet is lost, then it will take us at least a 100 milliseconds until the one who sent that packet will know about that – anything lower than that won’t allow the receiver to complain. Usually, it will take a bit more than 100 milliseconds.
For VoIP, we are looking to lower the latency. Otherwise, the call will sound unnatural – people will overtalk each other (happens from time to time in long distance calls for example). Which means we can’t really wait for these retransmissions to take place.
Which is why VoIP, in general, and WebRTC in particular, chose to use UDP to send its media streams. The concept here is that waiting will cause a delay for the whole duration of the session reducing the experience altogether, while the need to deal with lost packets, trying to conceal that fact would cause minor issues for the most part.
With WebRTC, you want and PREFER to use UDP for media traffic over TCP or TLS.
WebRTC ICE: Preferences and best effortWe don’t always get what we want. Which is why sometimes our sessions won’t open with WebRTC over UDP. Not because we don’t want them to. But because they can’t. Something is blocking that alternative from us.
That something is called a firewall. One with nasty rules that… well… don’t allow UDP traffic. The reasons for that are varied:
- The smart IT person 30 years ago decided that UDP is bad and not used over the internet, so better to just block it
- Another IT person didn’t like people at work bittorrenting the latest shows on the corporate network, so he blocked UDP traffic of the encrypted kind (which is essentially how WebRTC media traffic looks like)
This means that you’ll be needing TCP or TLS to be able to connect your users on that WebRTC session.
But – and that’s a big BUT. You don’t always want to use TCP or TLS. Just when it is necessary. Which brings us to ICE.
ICE is a procedure that enables WebRTC to negotiate the best way to connect a session by conducting connectivity checks.
In broad strokes, we will be using this type of logic (or strive to do so):
The diagram above shows the type of preferences we’d have while negotiating a session with ICE.
- We’d love to use direct UDP
- If impossible then relay via a TURN/UDP server would be just fine
- Then direct TCP connection would be nice
- Otherwise relay via a TURN/TCP or a TURN/TLS server
UDP comes first.
When is TCP (or TLS) good for WebRTC media?The one and only reason to use TCP or TLS as your transport for WebRTC media is because UDP isn’t available.
There. Is. No. Other. Reason. Whatsoever.
And yes. It deserved a whole section of its own here so you don’t miss it.
TCP for me is a last resort for WebRTC. When all else fails
When will TCP break as a media transport for WebRTC?The moment you’ll have packet loss on the network, TCP will break. By breaking I don’t mean the connection will be lost, but the media quality you’ll experience will degrade a lot farther than what it would with UDP.
Packet loss due to congestion is going to be the worst. Why? Because it occurs due to a switch or router along the route of your data getting clogged and starting to throw packets it needs to handle.
Here are all the things that will go wrong at such a point:
- TCP will retransmit packets – since they weren’t acknowledged and are deemed lost
- Retransmitting them will take time. Time we don’t have
- For a video stream, in all likelihood, the packet loss will be translated to a request to a new I-frame
- So the sender will then generate a new I-frame, which is bigger than other frames
- This in turn will cause more data to be sent over the network
- And since the network is already congested… this will just worsen the situation
- Here’s the “nice” thing though. TCP is retransmitting the lost data
- So we now have data we don’t need being sent through the network
- Which is congested already. Causing more congestion. For things we’re not going to use anyways
- It is actually hurting our ability to send out that I-frame the receiver is trying to ask for
- We’re also running on top of TCP, so there’s no easy way for us to know that things are being lost and retransmitted since TCP is hiding all that important data
- So the moment we know about packet loss in WebRTC is way too later
- No ability to use logic like intra packets delay (that’s smart-talk for saying figuring out potential near-future congestion, which also feels like smart-talk)
- And no way to employ algorithms to correct congestion and packet loss scenarios quickly enough
Bottom line – TCP causes packet loss issues to worsen the situation a lot further than they are, with a lot less leeway on how to solve them than we have running on top of UDP.
The assumptions TCP makes over the data being sent are all wrong for real time communications requirements that we have in protocols like WebRTC
Time to learn WebRTCI’ve had my fair share of discussions lately with vendors who were working with WebRTC but didn’t have enough of an understanding of WebRTC. Often that ends up badly – with solutions that don’t work at all or seem to work until they hit the realities of real networks, real users and real devices.
I just completed a massive update to my Advanced WebRTC Architecture training course for developers. In this round, I also introduced a new lesson about bandwidth estimation in WebRTC.
Next week, we will start another round of office hours as part of the course, letting those taking this WebRTC training ask questions openly as well as join live lessons on top of all the recorded and written materials found in the course.
If you are planning to use WebRTC or even using WebRTC, there isn’t going to be any better timing to join than this week.
Learn more about my WebRTC trainingThe post Why you should prefer UDP over TCP for your WebRTC sessions appeared first on BlogGeek.me.
Why CPaaS is losing the innovation lead to UCaaS
It seems like CPaaS vendors have grown complacent compared to the rapid innovation coming from UCaaS vendors. This makes no sense.
CPaaS has been leading the innovation when it comes to how developers build communication products. This has been the case ever since CPaaS was coined. But now, the trend is changing. This is doubly true for WebRTC and video communication services. UCaaS vendors have taken the lead in innovation and setting the pace of the market, leaving CPaaS vendors behind.
Can this trend be reversed? Is this a bad omen for CPaaS vendors competing in video use cases?
Table of contents- Predicting future communication trends
- The promise of CPaaS
- Pandemic requirement shifts
- CPaaS during the pandemic
- UCaaS during the pandemic
- Pandemic valuations
- The differentiation dilemma & Build vs Buy
- Wake up and smell the coffee
I used to work at RADVISION. The company specialized in video conferencing equipment but was split into two business units. The one I was a part of licensed VoIP software stacks to developers. You could say that what we did predates CPaaS. We didn’t have the cloud or server APIs but we sure did have SDKs.
In each and every townhall the company had, the CEO used to mention that our business unit was a precursor of the industry. Whatever requirements we’ve seen, whatever trend we experienced in sales (increase or decrease) was just an indicator of what is to come in the market in 3 years or so. The reasoning was simple – we licensed to developers, which then built their products and put them to market. Development cycles being as they were, 3 years was a good estimate.
Fast forward to today, and you have CPaaS vendors (the technology licensors of communication development tools) and the rest of the industry. And the large part of the rest of the industry is UCaaS.
The thing is, UCaaS vendors are no longer waiting for CPaaS vendors to innovate – they are just doing it on their own.
The promise of CPaaSCommunication Platform as a Service. What is it for anyways?
The whole purpose of CPaaS is to reduce the time to market for developers. Make it easier to get things done with communications by developing all the nasty little details for you.
Call it low code. Call it SDK or API or whatever.
I did an interview with Jeff Lawson, CEO of Twilio years ago. There Jeff explains the essence of Twilio – why he started the company. And the reason is to solve the communication problem for companies so they can focus on building great customer experiences.
Remember this one. We will be back to this interview a wee bit later.
Pandemic requirement shiftsThen the pandemic hit. And with it, a change in what communication requirements looked like around the world for all use cases.
4 distinct changes took place:
#1 – meetings became largerWe had large meetings before. The difference was that we connected rooms with groups of people in each room. Now? Everyone’s joining from his own place.
A meeting with 20 people in 3 rooms became a meeting with 20 people from 20 rooms. We will be back in the office, but the requirement for bigger meetings, with more people joining remotely will still be there with us.
Look at the start of this session from last year’s Kranky Geek virtual event.
Here Li-Tal Mashiach, Senior Engineering Manager at Facebook in the Messenger team explains what they’ve seen as changes in the usage of video calls in Messenger. Look at around the 2:40 mark in that video.
#2 – more meetings for longer periods of timeThis one is obvious. Or is it?
Almost all vendors have seen a significant growth in both the number of video sessions conducted on their platforms as well the length of these sessions.
Scale had to be dealt with across these two axes.
You need to make sure you can carry conversations that now take hours on end instead of minutes:
- My daughter had 4+ hour long sessions with her friends during lockdowns going well into the night. They talked, are, cooked and did whatever the hell teenage girls do together – just remotely
- My son is still video calling with his cousin while playing Fortnite on his Xbox. And that usually lasts… well… until we stop them forcefully
In both cases, much of the interaction is just ambient video. They do things together or apart and just have these social interactions take place because they can’t meet. Funny enough, my son and his cousin aren’t stopping it now even though everything is open – that’s because meeting physically requires a 20 minute car ride…
How does that change the focus? How do you maintain servers, upgrade and update them when sessions can take hours on end on a machine? Does it mean the media servers also need to be stabler in how they operate?
And what about the number of sessions? Is it that easy to scale 10x or more your current traffic? This isn’t a simple question to contend with. Google shared their own challenges with scaling Meet which makes for a fascinating read. I had my share of vendors to help with best practices in scaling their WebRTC infrastructure during the last 15 months as well.
#3 – more networksBack to that Kranky Geek video by Facebook. They saw an increase in desktop access. More than they had expected being mobile first.
I’d argue that we’ve all seen more variety in devices and networks. My apartment went from 1 video calling user to 4 video calling users in a matter of a day. Billion people or more who never went on a video call have done so and will continue to do so at least some of the time.
What devices do these billion people have? What does their home network look like?
If you look at the technology adoption curve, these aren’t the innovators or early adopters. They aren’t even the early majority. They include both the late majority and the laggards.
This means we’re facing a lot more variance in devices and networks. In the need to deal with lower end capabilities and resources available. And to deal with having these large groups take place with a larger variety of the differences across devices.
#4 – more placesThe best part of video calling during the lockdowns and up until today is taking a peak at other people’s home office. You get to see a piece of who they really are outside “work”.
These places are almost always less than ideal.
- Dogs and cats being part of the background
- Kids. Lots of kids. Popping into the screen. Making noise
- People walking in the back doing laundry, cooking, running after kids. The works
- Construction noises from outside
- Poor lighting conditions
Everything you can think of that affects the audio and video quality due to external sources will be there. And you can’t always ask the user to go purchase a better camera, change where he is sitting or replace his device.
It becomes a technical problem to solve many of these issues, especially when the service offers ad-hoc connectivity for its users.
CPaaS during the pandemicCPaaS were supposed to help vendors build their products. Look at future needs and cater for them. And for the most part they do. But somehow during this pandemic, it seems that many of them have failed to do so.
I’ll look at Twilio here – and not because they are the only vendor with these issues – but because they are the biggest CPaaS vendor and the precursor of the industry.
Last year after Twilio’s Signal 2020 event I wrote that I expected more of them:
For me this says that Twilio hasn’t invested in video as much in the last year or two. If they had, they would have announced something more thrilling and interesting. Maybe larger meetings, above 50 participants? Broadcasting capabilities? Noise suppression? Something…
Since I wrote that, 8 months have passed. Meeting sizes for Twilio Programmable Video are still limited to 50 participants. There are no broadcasting capabilities. No noise suppression. No background blurring. Nothing.
I can’t even recall any real additional feature that Twilio introduced for Twilio Programmable Video since that Signal event. Maybe updates and improvements to their React reference app, but nothing more.
Most other vendors showed similar inclination and introduction of new features throughout the pandemic. It seems like the trend now for video APIs is to focus on embedded iframes for faster development. These have been discussed and experimented with years ago, and now seem to be finding new traction and interest.
It takes more time to develop features in CPaaS than it does on other platforms. The reason for that is the CPaaS vendors need to do 2 things others don’t have to deal with:
- Make the feature generic, solving a problem for more than a single use case or customer
- Document the feature properly, so that developers will be able to figure out how to use it
But let’s face it. These new requirements have been around for 15 months now…
There are obviously a few caveats here:
I am griping here about video
CPaaS has grown during the pandemic, so this hasn’t hurt them. Yet
Video is usually a small percentage of traffic and income for a CPaaS vendor
UCaaS during the pandemicUCaaS shows a stark contrast to how CPaaS responded.
Many of the leading vendors have added background blurring and replacement, noise suppression and other features and capabilities. They have done so in breakneck speeds and they seem to be spewing out new features every week or so.
This isn’t limited to a single vendor. Out of the top of my head: Zoom, Microsoft Teams, WebEx, Google Meet and RingCentral all introduced these features in the past year. And all of them seem to be investing further into these areas while pushing forward other initiatives they have, each with its own focus.
Remember Jeff’s interview? I asked him if he believed UC vendors should develop their services on top of CPaaS. This is what he answered:
Yeah. I believe that companies whose primary business is communications can and definitely should and would get competitive advantage by using a platform like Twilio to build upon. The reason why is this. It used to be when those UC companies started, their core competency was making the phone ring. Then they’d add some software functionality on top of it, sure, but the vast majority of what they worried about was how do I make the phone ring? The problem is Twilio has democratized that ability.
[…]
The existing UCaaS vendors, they would be wise to build on top of the same platform that any developer in the world can come and start to compete with them on. If they don’t, those independent software developers, they can actually start and build companies that are really compelling competitors, because they don’t have to focus on the low level bits. They’re focused on the things customers really care about, which is features, functionality, and the user experience that matters.
While mostly true, this doesn’t hold water these days for video communications. Relying on CPaaS vendors means you need to figure out the feature set that is necessary to be a compelling competitor yourself – larger groups, background replacement, noise suppression, …
CPaaS vendors need to put their act together in the video domain, or start losing customers that will just go build this on their own. Especially when we see Zoom coming up with their Video SDK and becoming a direct competitor to CPaaS vendors.
UCaaS vendors are having their own headaches in the market due to the dramatic changes that Microsoft and Google are bringing into this domain. I’ll leave that for a future article.
Pandemic valuationsThe pandemic also changed the dynamics in communication vendor valuations, shifting the focus to slightly different domains.
Hopin and Clubhouse, which I already touched on in my previous article about the new era in WebRTC.
Agora (video CPaaS vendor) had a hugely successful IPO, followed by another spike due to the popularity of Clubhouse (who is using them). They are now back to roughly their initial IPO price point.
Twilio (CPaaS) increased in their valuation throughout the pandemic. My guess is that this is mostly due to the increased use in voice and SMS. Less so in video, where they invest a lot less.
Zoom. Need I say more?
The differentiation dilemma & Build vs BuyHow does one differentiate then?
- CPaaS vendors haven’t done enough during the pandemic to enable differentiation for the video use cases
- The same CPaaS vendors also haven’t differentiated enough from one another – at least not on the surface level
- Build on top of your CPaaS vendor the missing features (if possible)
- Build your infrastructure in-house
I am seeing the following trends in CPaaS adoption and use. They used to be related to pricing, but now they are becoming more and more related to feature sets and differentiation needs:
Most enterprises stick with the use of CPaaS vendors. They rely on them for their communication needs. They will switch from a CPaaS vendor to another CPaaS vendor if they can get better pricing or if their current vendor is lacking features (or provides poor support).
Technology vendors and startups will pick either CPaaS vendors as their starting point or prefer going it alone from the get go. Those that become hugely successful will end up actively working on replacing the CPaaS vendor with their own infrastructure. They will see that as an imperative a lot more than their enterprise brethrens.
Unified communication vendors will continue as they are. Assuming that communication infrastructure is core to their business and will work towards maintaining their own knowledge and experience in the area – doubly so after the pandemic.
Wake up and smell the coffeeCPaaS vendors should wake up and smell the coffee.
The world has changed. Drastically.
There’s no going back to the old ways – even without quarantines.
I believe that there’s a competitive advantage waiting here. CPaaS vendors have been shying away from these requirements. The first ones to come out with actual solutions and feature capabilities that will ease the development of customers will win due to this differentiation.
The reason this hasn’t happened so far is that traditionally, such things weren’t catered for directly by CPaaS vendors – it is out of their comfort zone. This leads to an opportunity that is up for the taking.
—
On a similar note, after running successfully the Future of Communications workshop with Dean Bubley, we decided that it is both information packed and fun to do. If you are interested in a private session for your company – let us know.
The post Why CPaaS is losing the innovation lead to UCaaS appeared first on BlogGeek.me.
FaceTime finally faces WebRTC – implementation deep dive
Deep dive analysis on how FaceTime for Web uses WebRTC. Philipp "Fippo" Hancke uses webrtc-internals, Wireshark, and reviews the JavaScript implementation to expose Apple's implementation details.
The post FaceTime finally faces WebRTC – implementation deep dive appeared first on webrtcHacks.
WebRTC: The end of an era (and the dawn of a new one)
After 10 years, we are at the dawn of a new era for WebRTC. This one is going to focus on differentiation and will bring with it new dominant players into the field.
There’s a change in the air. I think it started towards the end of 2019, but now it is quite obvious to see. WebRTC is changing – not the specification but rather who is using it and how it is used.
Table of contents- A look at the history of WebRTC
- WebRTC 1.0
- The pandemic
- Zoom
- WebRTC musical chairs
- WebRTC “winners” of 2021
- Welcome to the new WebRTC
There’s a slide I showed last week in the workshop of the future of video and real-time communications. It resonated with me with the latest news of Justin Uberti leaving Google. So much so, that I decided to record it separately and share it here as well:
We’ve moved from exploration to growth and now into differentiation when it comes to WebRTC.
What got us there exactly?
WebRTC 1.0We’ve got that WebRTC 1.0 milestone behind us now.
I haven’t written any special article about WebRTC 1.0, because the main question you need to ask yourself is what changed?
And the real answer is nothing.
The work towards WebRTC 1.0 was important and this is an important milestone. But browser vendors already implemented WebRTC. And vendors already used WebRTC in browsers and native applications as if this was a done deal already.
If you were using WebRTC before, then nothing has changed for you since the announcement of WebRTC 1.0.
And if you haven’t used WebRTC yet, then why start now? What was holding you back so long? The fact that you weren’t sure if it is here to stay???
Having WebRTC 1.0 out is an important milestone. More a symbol and a signpost than anything else.
The pandemic The pandemic had a positive effect on WebRTC adoptionThe pandemic got us all quarantined and changed everything.
There’s no new normal to talk about yet, but if you’re believing things are “going back to normal” then you’re wrong.
To put simply:
- More businesses than ever before are just “fine” with employees working from home (or remotely)
- Some businesses are fine doing that ALL the time, permanently
- Other businesses are just as happy if you come to the office only some of the days of the week
- More employees want to work remotely
- Some employees simply don’t want to go back to the office. They’re just fine working from home. They will actively seek such jobs
- Other employees are fine working a few days in the office and the rest remotely, so they don’t have to commute as much while still socializing face to face with their peers
- ALL businesses want to sell more. They couldn’t care less if their clients are buying stuff locally or remotely
- More customers are now fine with purchasing remotely or even being served remotely
These changes are bringing with them a lot of new demand, new use cases and new requirements.
What we focused on with WebRTC up until 2020 was suitable for the “old” pre-pandemic world. What we need to focus on now is on the “new” post-pandemic world, one which has slightly different requirements.
Zoom Is Zoom the exception to prove the rule?Even before the pandemic, Zoom’s IPO has been phenomenal.
After the pandemic, Zoom has become a household name.
Pick any communication service you wish from any vendor in the globe. Randomly pick 100 people from the world’s population. How many of them will know that vendor or service, and how many of them will know Zoom?
Zoom doesn’t really use WebRTC, so why should you?
This is an important question. The appropriate answer is probably one of context. Your context is different from Zoom’s.
- Using proprietary real-time video is a hard problem to solve, so why not use WebRTC instead of solving it yourself?
- Nobody knows you yet, so whatever Zoom has going for it might not necessarily fit your situation
- Zoom is probably installed on most machines today. Your app isn’t. How will you entice potential users to download and install your app?
And yet the WebRTC industry, its stack, the browsers and vendors are consistently being compared to Zoom.
Your ability to compete with Zoom on quality and connectivity is greatly dependent on Google, and what they decide to do with WebRTC.
You are not in full control over your destiny.
WebRTC musical chairsThere were a few changes in the people who are working and dealing with WebRTC directly recently. I want to discuss 3 specific cases that I think mark the end of an era.
Dr Alex Gouaillard, CoSMo and MillicastDr Alex Gouaillard passed away in April 2021.
Alex has been a known figure in the WebRTC community. His voice on subjects, his passion and his work has made its mark on our industry. He will be sorely missed.
In recent years, Alex focused heavily in the area of live streaming, trying to solve the challenge of broadcasting a WebRTC stream to many participants. He has been a vocal proponent of the use of AV1.
It will be interesting to see who will pick the mantle here and fill the void in explaining and promoting these use cases now.
Nils Ohlmeier, Mozilla (now 8×8)Nils Ohlmeier has been “the guy” from Mozilla who represented WebRTC in Firefox.
He shared the work Mozilla is doing in Firefox for WebRTC in last year’s virtual Kranky Geek event as part of the browsers panel we did:
Nils switched employers this month, starting to work at 8×8 in the role of Principal Engineer. He will be contributing to the Jitsi codebase and its growth. While Jitsi has a large and vibrant ecosystem, is it anywhere near the size and complexity Mozilla had to deal with?
Who is going to take this role at Mozilla?
Is Firefox interesting as a browser for WebRTC developers and users anymore?
Was it time to move on now that the biggest challenges of WebRTC for browser vendors is “behind” us?
To me, these questions more than anything else mark the change in times.
Justin Uberti, Google Stadia (now Clubhouse)Justin Uberti was there from the start when it came to WebRTC.
He is considered by many the lead engineer behind the Google Chrome team of WebRTC, and he was part of the original duo (not only the app) – Serge Lachapelle & Justin Uberti.
Justin moved on from the WebRTC team to Google Stadia at the end of 2019. He worked on Stadia related features before that as well.
This month, he decided to move on, leaving Google altogether, pursuing new activities. Justin is staying in the WebRTC industry, as his new role is Head of Streaming Technology at Clubhouse.
Here’s what Justin had to say at Kranky Geek 2018 during Google’s WebRTC update session:
It is truer today than it was in 2018…
Definitely the end of an era.
WebRTC “winners” of 2021In 2017 I’ve written about 10 Massive Applications Using WebRTC.
That was 3.5 years ago and before anyone thought about quarantines or Zoom.
Fast forward to today, and that list is going to look different.
Two vendors I want to highlight here are Hopin and Clubhouse. They are different from the other vendors we’ve seen in the past who are making use of WebRTC.
HopinHopin is a virtual events platform founded in June 2019, a bit less than two years ago. They couldn’t ask for a better timing (maybe start 6 months earlier?).
Within that timespan, Hopin managed to raise a whopping $571.4M in total and made 4 acquisitions (including StreamYard, Streamable and Jamm).
There are many virtual events platforms ever since the pandemic started but Hopin seems to be the biggest and most widely known one. They have shown that they aren’t shy of acquiring the technologies they need in order to get their feature set where they want it to be.
In 2019, who would have thought a virtual events vendor would be worth $5.65B in valuation by 2021?
Hopin has a nice warchest that they can use to grow their business, attract top notch developers and acquire or acquihire their way to success.
ClubhouseAnother interesting vendor is definitely Clubhouse.
Everyone wants to be Clubhouse these days, but there’s still only a single Clubhouse out there.
Clubhouse started life with the pandemic, in March 2020. After only 14 months it has a valuation of $4B and has been funded well over $100M ($110M by series B in January this year, and another undisclosed series C in April). That’s quite a feat for a voice only, iOS only (until recently) service.
It has a warchest to rival that of Hopin and the same kind of hype behind it to allow it to do practically anything it wanted.
Clubhouse still lacks a real business case, but it doesn’t seem to be stopping it.
Clubhouse is known to be using Agora as their CPaaS vendor, but that may soon change. They hired Justin Uberti from Google, and the only reason for that to me seems to be the desire to own and control their infrastructure.
GoogleGoogle is still the big winner of WebRTC.
If you look at what features are added to WebRTC, then the answer to that is whatever Google needs for its own uses.
These uses now include Google Meet, Google Stadia and Google Assistant.
If your use case has the same requirements in general then you’re in good shape. If you are going “off the reservation”, then prepare for a life of misery if there’s something missing that you need and isn’t in Google’s own set of requirements.
WebRTC is open source up to a point. Not because the code isn’t open and available to all, but because the main implementation is owned and controlled by Google and the main browser you’ll need to work with is Chrome.
Welcome to the new WebRTCFrom now on, WebRTC is going to be different.
Talking heads are still an important part of it, but the focus is shifting from a “video chat” or “video conferencing” service into a communication service that is unique. What that is exactly is hard to say, but suffice to say that WebRTC is there in the background.
And fading to the background is exactly what we wanted from WebRTC – the technology is only great once we start forgetting it is there.
The post WebRTC: The end of an era (and the dawn of a new one) appeared first on BlogGeek.me.
How to Leverage the AWS WebSocket API for Serverless WebRTC signaling
How to use the AWS API Gateway WebSocket API functionality with Lamdba functions to implement a serverless WebRTC signaling architecture
The post How to Leverage the AWS WebSocket API for Serverless WebRTC signaling appeared first on webrtcHacks.
Interoperability and standardization in a world dominated by WebRTC & Zoom
Rethink the way we look at interoperability and standardization in communications, now that we live in a WebRTC & Zoom world.
We live in a different world. This video popped up in my Facebook as something I shared a year ago:
It is in Hebrew, but there are enough words in English there to make it quite apparent. This comedian is trying to explain to his mother over the phone how to use Zoom.
Today? Everyone knows how to use Zoom. Or WebRTC.
The transformation of communication technology- Rewind 20+ years ago
- The rise of the smartphone (and the cloud)
- A new way to look at communication standards: WebRTC
- Zoom and the pandemic
- Workshop: The Future of Video & Realtime Communications
I started my professional adult life in a video conferencing company. There, I lived and breathed interoperability and standards for the better part of 13 years. I have a few contributions that got approved at the ITU and 3GPP. I’ve been to interoperability events and even hosted two of those in Israel.
At the time, the mindset was a telephony one:
- There is a single way of doing things. We call that the standard specification
- Vendors can implement different components of that specification
- A buyer can purchase any component from any vendor and miraculously, his new purchase would “speak” to all other components on the network
- Why? Because they are all interoperable. Per the standard
There were two main reasons why we wanted such a world to live in:
- Lower the barrier of entry. For a single company to develop it all requires huge budgets. Smaller vendors couldn’t take that risk and we wanted the innovation
- Monopoly power and vendor lock in. We wanted to give clients choice in what they purchased and have the ability for them to mix and match and not be locked in to a specific vendor for life
Then Apple came with the iPhone and changed. Everything.
From embedded platforms, the smartphones became open programming platforms (open even within the closed gardens of their app stores).
Today, many of the embedded devices include an Android operating system, making it ever easier to develop software for them.
This brought with it a new kind of openness:
- You didn’t have to purchase a device that adhered to a standard specification
- The alternative was to download or install the necessary communication software instead
This didn’t mean standards were unimportant. It meant that interoperability became less interesting. Vendors could now bake their own proprietary additions on top of the standards that give extra features without the need to think too much about interoperability with other vendors – that’s because your client now brings his own device (BYOD) and you supply the software application to connect to the infrastructure.
Oh, and by the way – that infrastructure? It is now built in the cloud. And the cloud enables rapid development and hyper growth. Which again means that caring about interoperability becomes less of an issue between the client device and the cloud infrastructure – vendors are more interested in interoperability between their infrastructure components or with external service providers – via gateways.
This turned communications from a service into just another application on our phones.
A new way to look at communication standards: WebRTC WebRTC brought communications to the browser, making it into a feature{kind=link}
WebRTC came to our world about 10 years ago and changed the paradigm again.
Where the smartphone and the cloud reduced our dependency and need for interoperability, WebRTC reduced our dependency and need for standardization.
We still need standardization – after all, WebRTC is a standard.
But the standardization we care about is mostly the browser implementations versus the specification (and interoperability between browsers). Other than that? We couldn’t care less.
The client side is no longer even a software application. It is a bunch of JavaScript lines of code that get executed inside a web browser that supports WebRTC. We can still do applications, and we do, but the concept and the intent is the same – standardization across vendor’s components and devices is now overrated and mostly unnecessary.
If we need standardization and interoperability, we let gateways do it. As we did in the era of the smartphone.
WebRTC also made communications more accessible. Web developers could now use it, and you could easily embed and stitch it right into your application as a seamless part of your business process flow.
This turned communications from a service or an application into a feature in another service or application.
Zoom and the pandemic The pandemic made video communication commonplace, enabling Zoom to turn it into a platformThen the pandemic came and made a world a lot smaller. It made sure we all know how to use video communications.
Zoom became a household name across the globe and turned into a noun.
Zoom is proprietary. It doesn’t even use WebRTC.
No standards. Which lead to a lot of security missteps.
But it worked. And now Zoom has a Client SDK a Video SDK and Zoom Apps. With the intent of making their infrastructure and technology integratable with anything and everything.
This is an attempt to turn communications from a service or an application or a feature into… a platform.
Workshop: The Future of Video & Realtime CommunicationsA few weeks ago, I had a conversation with Dean Bubley. We wanted to do something together, and decided to create a joint workshop.
The question of the role of standardization and interoperability is one of those we are going to tackle in the upcoming workshop.
If you are interested in joining the workshop, register below. There’s an early bird discount that is available only until the end of this month.
REGISTER TO THE WORKSHOPThe post Interoperability and standardization in a world dominated by WebRTC & Zoom appeared first on BlogGeek.me.
Lyra, Satin and the future of voice codecs in WebRTC
There are new audio codecs in town: Google Lyra and Microsoft Satin. Both banking on AI-based voice coding, and both will be fighting for inclusion in WebRTC.
{kind=link}
Right on the heels of the changes we see in video codecs in WebRTC, with AV1 coming into the stage, and HEVC making an entrance in Apple devices, we now have a similar (?) story with voice codecs. Microsoft announced its AI-powered voice codec Satin in February. A week later, Google reciprocated in kind, announcing its low bitrate codec for speech compression Lyra.
Why now? What are the similarities and differences between these codecs? Where are they headed? And what does that mean to WebRTC and to you?
Table of contents- Audio codecs in WebRTC
- The two extremes in audio codecs: Low bitrate vs lossless
- AI and audio codec generations
- The Opus spec
- Microsoft Satin
- Google Lyra
- A multi-codec audio future for WebRTC?
- FAQ on Satin and Lyra
It makes sense to start this by explaining a bit about audio codecs in WebRTC.
WebRTC has mandatory to implement codecs. For audio/voice, these codecs are G.711 and Opus.
For all intent and purposes G.711 is there as a legacy codec, to deal with narrowband audio. The result of which is low quality, unresilient audio. Using G.711 is mostly reserved to connect it with the telephony networks, and even there, I wouldn’t recommend it as a solution.
Opus is the main voice codec in WebRTC. It offers a highly flexible solution capable of handling anything from narrowband to fullband stereo and at low bitrates. You can read more in this article I’ve written years ago: The Rise of Opus to HD Voice Domination.
Opus is almost 10 years old. It has been created by meshing two separate codecs: SILK (for speech) and CELT (for music). The pandemic of 2020, and the increased reliance on virtual meetings has started to show its age and its limitations. Opus is a great codec, but these days, we can probably do better.
How Opus works, from my Advanced WebRTC Architecture Course The two extremes in audio codecs: Low bitrate vs lossless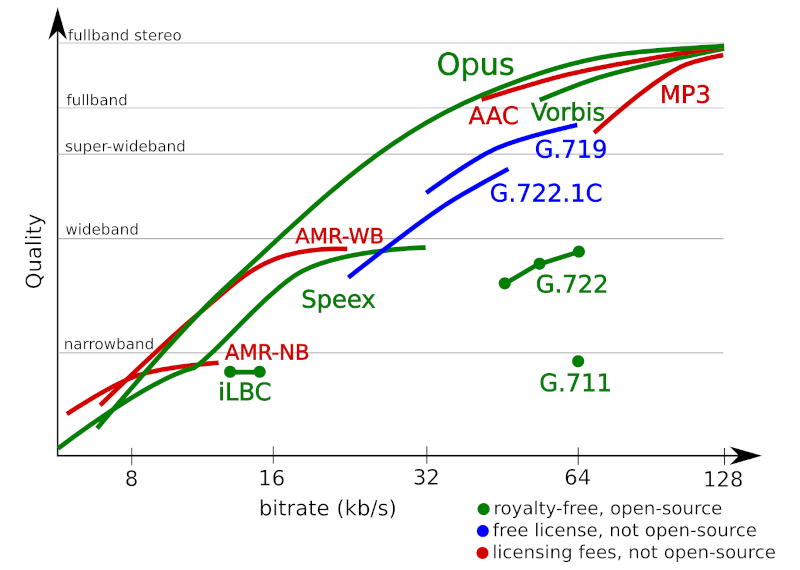{kind=link}
So what are the missing pieces? The things that Opus can’t get done on its own? There are two such areas that are actively being explored, and they are two extremes: highest possible audio quality and lowest possible bitrate.
Highest possible quality: Lossless audio codingOne extreme (unrelated to Lyra and Satin), is the strive for the highest possible audio quality. Getting there requires the use of lossless audio coding.
For all intent and purpose, what we do in VoIP today, and by extension in WebRTC, is use lossy coding. This means that we compress the audio and video in ways that don’t really allow us to reconstruct the original audio or video accurately, but instead it gets us “close enough” to there. It does that by trying to “get rid” only of information that we humans can’t discern – things the human eye and human ear would miss anyways.
As a crude example, I never did hear the difference between vinyl, cassettes and CDs – at least not enough for it to matter for me. On the other hand, I had a friend who complained that CDs don’t have the audio quality of vinyl records.
The most known lossless audio codec is FLAC. It has nothing to do with WebRTC. Yet.
Lowest possible bitrate: AI based compression{kind=link}
In the other end of this spectrum lies the lowest possible bitrate we can comfortably reach.
It turns out that Opus is good, but not great.
At a time where bandwidths are increasing, why do we even discuss getting voice codecs into lower and lower bitrates? What would be the incentive?
These questions are doubly important considering the fact that we’re heading towards a remote video filled world. And we know that video takes up considerably more bitrate than voice, so why care so much about voice bitrates?
One reason is simply the fact that we’re now communicating remotely a lot more. We do that more, and there are also a lot more people communicating online. From everywhere. This means that not all of them are going to be on great networks at all times, and even when they are, others are going to strain these networks with their own traffic. Google calls this “the next billion” – the next billion people joining the internet, which means people with less means and by extension less bandwidth.
The other reason is the fact that we’re growing bigger. More sessions. Bigger sessions. Widely spread. If we can even reduce a fraction of the bitrate, that would reduce the strain on our networks, servers and costs of running services.
I am also guessing that the big video meeting vendors got to learn a few interesting things during the pandemic. One of them is that voice is the most important part of a video call. If you don’t deliver your voice properly, video won’t matter. And for that, you need to make it leaner and meaner than it is today.
{kind=link}
How do you make voice compression for an audio codec better?
AI and audio codec generationsI’ll be using machine learning (ML) and artificial intelligence (AI) interchangeably here. These terms have been butchered by marketers so much, that they are now indistinguishable anyway.
Better in the case of audio codecs is going to be a new generation of codecs. In a way, a migration from the old way of doing things (rule engines and heuristics) to our brave new world of machine learning and artificial intelligence.
Machine learning is where the future lies when it comes to most of our algorithms. Especially with the ones that make extensive use today of either rule engines or heuristics – both of which are found in abundance in real time media processing pipelines (=WebRTC). We started seeing this trend seeping into real time communications and WebRTC somewhere in 2018. After the initial hype, we found out the many challenges of adding machine learning. In 2020, it seemed like the path became somewhat clearer: noise suppression and background replacement solutions assisted with AI. For the rest? We understood collectively that we should first squeeze the lemon of optimization before resorting to AI.
It is now time to look at AI in media compression as well. We’ve seen this take place already in baby steps. At Kranky Geek 2019, Shawn Zhong of Agora, explained how AI can be used to improve encoding efficiency:
A year later, NVIDIA introduced Maxine, a platform capable of using AI to “reconstruct” a person. Effectively creating a kind of a compression algorithm.
Research around AI compression is flourishing. There is already an AI specific standards organization called MPAI (Moving Picture, Audio and Data Coding by Artificial Intelligence) – still small, but this may change in the future. And then there’s Mozilla’s Common Voice, an open source, high quality, labeled multi-language dataset for training language related models.
{kind=link}
It makes sense then, that audio would be a prime target for AI based compression as well. Here, Microsoft took the first public shot, and Google immediately followed suit.
The Opus specTo understand where Microsoft Satin and Google Lyra are headed, let’s first review how Opus works:
- Opus has a range of 6-510 kbps of compression
- Realistically, for WebRTC, it would be 6-40kbps, and in most cases ~26-30kbps
- It runs the gamut of narrow band up to full-band stereo
- Latency of 26.5ms, making it quite powerful for real time since it adds very little inherent delay of its own
- As mentioned above, for speech, Opus uses a modified SILK implementation. For music it uses CELT, another audio codec. It can use them simultaneously as needed. And interestingly enough, it has a small machine learning model that decides what to use by classifying the audio input as either speech or noise
Now let’s look at what we know so far about the two new audio codecs.
Microsoft SatinMicrosoft Satin is being positioned as an AI-powered audio codec to replace Silk.
Silk is used by Skype and was adopted as the basis for Opus as well. Here’s what Satin can do based on Microsoft’s announcement:
- Super wideband speech starting at a bitrate of 6 kbps
- Full-band stereo music starting at a bitrate of 17 kbps
- Progressively higher quality at higher bitrates
- Provide great audio quality even under high packet loss
- Better redundancy algorithms to provide better protection under burst loss
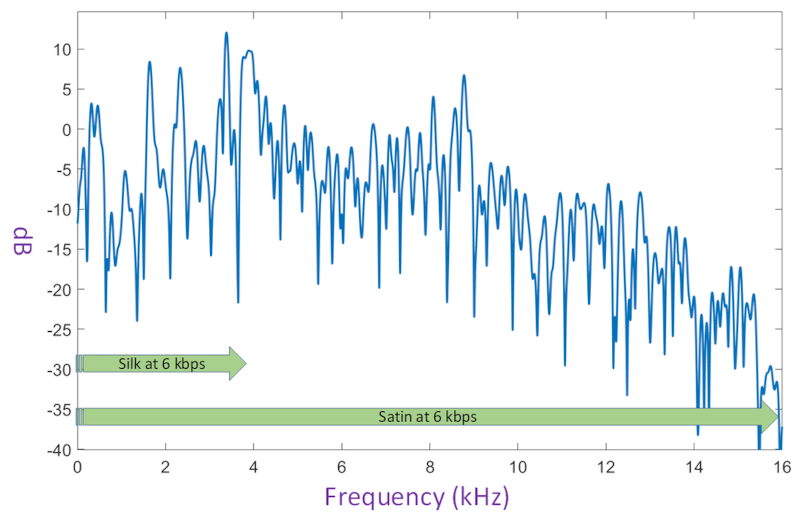{kind=link}
Satin wasn’t presented as a work in progress, but rather as a battle tested codec – Microsoft stated it is already being used by Microsoft Teams and Skype in 2-way calls. Obviously, with plans to extend it to group calls.
Satin is a brand new codec that is being designed to replace Opus altogether.
Google Lyra{kind=link}
Google’s announcement of Lyra came a week after Microsoft’s. In a way, it seemed a bit rushed.
Why rushed? Because of how the announcement is written. It reads similar enough to the Microsoft one but lacks the “currently deployed” paragraph. Instead it has a “currently rolling out” paragraph.
What is Lyra about? Based on Google’s announcement:
- Very low-bitrate speech codec
- Processing latency of 90ms (on the slow end of the spectrum of real-time voice codecs)
- Designed to operate at 3kbps
- Currently optimized for the 64-bit ARM android platform
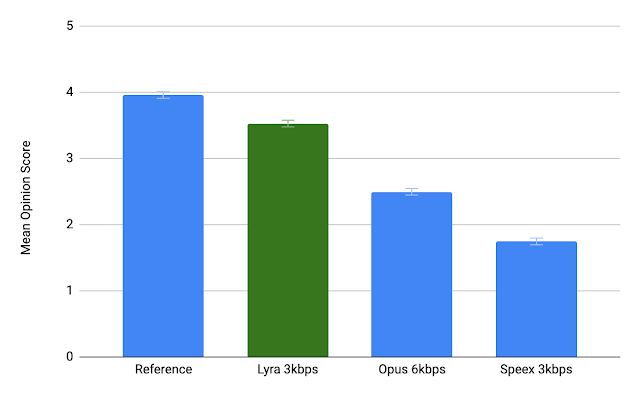{kind=link}
Lyra is intended for SPEECH and not for AUDIO. It isn’t a replacement of Opus in any way.
Interestingly, Google believes that coupled with AV1, it can offer decent video conferencing experience at dial-in modem bitrates of 56kbps.
Lyra is being rolled out to Google Duo for very low bandwidth connections scenarios. But that’s about it for the time being.
More recently, Lyra has been open sourced by Google. The reasons for this are varied, especially considering that many of the recent advancements of Google in AI around real time communications weren’t open sourced at all:
- Lyra came after Satin. They will both be fighting it out on being included in WebRTC
- It is superior to Satin (probably) at the very low bitrate of 3kbps, especially considering Satin was designed for 6kbps and above. But it is no match to Satin in higher bitrates, where Satin most probably beats Opus
- Google decided long ago that codecs should be free and open source (see the WebM project). As such, Lyra needs to play by these rules as well. Google might not see a competitive advantage here and would rather have this available across the board
Another thing you can achieve with Lyra is better redundancy for improved resiliency. With its very low bitrate, it is less of a constraint to add redundancy on top of it. You can check out this article on webrtcHacks by Philipp about audio redundancy encoding.
A multi-codec audio future for WebRTC?At the moment, both Lyra and Satin are nice bedtime stories. You can use them only inside the proprietary implementations of Google and Microsoft. And even then, in most cases you wouldn’t even know that to be the case.
Why was it important then to announce these efforts?
My hunch is that it has to do with standardization and WebRTC.
WebRTC needs some love and attention now in the audio front. For video, we’re going to have AV1, but what do we do about voice?
There are currently two alternatives out there that will make their move soon enough:
- Satin. As a 3rd optional codec in WebRTC. Microsoft will need Google’s approval/help to push this one forward by making it a part of Chrome, otherwise, it won’t gain enough popularity and will be kept proprietary and niche
- Lyra. This codec makes no sense to me as a standalone codec. Adding it to WebRTC “as is” will be quite challenging for developers to make use of. There are a few routes that can be taken here:
- Have it handle wideband and full-band better and in a way competitive to Opus and call it a day. That means competing head-to-head with Satin
- Shove it into Opus. Call it Opus 2.0. Opus already contains SILK and CELT. Why not LYRA as well? Let Opus decide which one to use when and be done with it. Since Lyra is already open sourced, that can be a natural next step…
- Get Google and Microsoft in the same room and see how to put Lyra inside Satin, find a 3rd name for it so no one gets pissed off that the other won the marketing game, and add that new codec into WebRTC
It is too early to say how this will play out. My bet is on more optional audio codecs finding their way into WebRTC – not the boring old ones, but rather the hip new ones. This will make audio codec selection for developers building services a wee bit harder, which isn’t a good thing in the long run. I’d rather see this pushed into Opus – or added as a single codec replacement to Opus. Something that would be easy to pick instead of Opus.
FAQ on Satin and Lyra ✅ Is Google Lyra equivalent to Microsoft Satin?No.
While both of these audio codecs operate at low bitrates and are powered by AI they are very different. Lyra is focused on narrowband only while Satin is about operating in super wideband.
Technically – yes.
Microsoft is already using Satin instead of Opus in Microsoft Teams and Skype for 1:1 calls. IT was designed with that goal in mind.
No.
Lyra was designed to work at low bitrates where Opus doesn’t do a good job today. When there’s enough bitrate, Opus offers better audio quality than Lyra.
No.
There are no public plans to add either of these codecs to the WebRTC specification or to browser implementations.
The post Lyra, Satin and the future of voice codecs in WebRTC appeared first on BlogGeek.me.
How Go-based Pion attracted WebRTC Mass – Q&A with Sean Dubois
Pion seemingly came out of nowhere to become one of the biggest and most active WebRTC communities. Pion is a Go-based set of WebRTC projects. Golang is an interesting language, but it is not among the most popular programming languages out there, so what is so special about Pion? Why are there so many developers […]
The post How Go-based Pion attracted WebRTC Mass – Q&A with Sean Dubois appeared first on webrtcHacks.
Pages
Using the greatness of Parallax
Phosfluorescently utilize future-proof scenarios whereas timely leadership skills. Seamlessly administrate maintainable quality vectors whereas proactive mindshare.
Dramatically plagiarize visionary internal or "organic" sources via process-centric. Compellingly exploit worldwide communities for high standards in growth strategies.
Wow, this most certainly is a great a theme.
Company name
Yet more available pages
Responsive grid
Donec sed odio dui. Nulla vitae elit libero, a pharetra augue. Nullam id dolor id nibh ultricies vehicula ut id elit. Integer posuere erat a ante venenatis dapibus posuere velit aliquet.
Typography
Donec sed odio dui. Nulla vitae elit libero, a pharetra augue. Nullam id dolor id nibh ultricies vehicula ut id elit. Integer posuere erat a ante venenatis dapibus posuere velit aliquet.