

News from Industry
End-to-End Encryption in WebRTC… 4 Years Later
We covered End-to-end encryption (E2EE) before, first back in 2020 when Zoom’s claims to do E2EE were demystified (not just by us; they later got fined $85m for this), followed by the quite exciting beta implementation of E2EE in Jitsi using Chromium’s Insertable Streams API. A bit later we had Matrix explain how their approach […]
The post End-to-End Encryption in WebRTC… 4 Years Later appeared first on webrtcHacks.
WebRTC recording challenges and solutions
Need WebRTC recording in your application? Check out the various requirements and architectural decisions you’ll have to make when implementing it.
A critical part of many WebRTC applications is the ability to record the session. This might be a requirement for an optional feature or it might be the main focus of your application.
Whatever the reasons, WebRTC recording comes in different shapes and sizes, with quite a few alternatives on how to get it done these days.
What I want to do this time is to review a few of the aspects related to WebRTC recording, making sure that when it is your time to implement, you’ll be able to make better choices in your own detailed requirements and design.
Table of contents- Record-and-upload or upload-and-record
- Multi stream or single stream recording
- Switching or compositing
- Rigid layouts or flexible layouts
- Transcoding pipeline or browser engine
- Live or “offline”
- Plan your WebRTC recording architecture ahead of time
One of the fundamental things you will need to consider is where do you plan the WebRTC recording to take place – on the device or on the server. You can either record the media on the device and then (optionally?) upload it to a server. Or you can upload the media to a server (live in a WebRTC session) and conduct the recording operation itself on the server.
Recording locally uses the MediaRecorder API while uploading uses HTTPS or WebSocket. Recording on the server uses WebRTC peer connection and then whatever media server you use for containerizing the media itself on the server.
Here’s how I’d compare these two alternatives to one another:
Record-and-uploadUpload-and-recordTechnologyMediaRecorder API + HTTPSWebRTC peer connectionClient-sideSome complexity in implementation, and the fact that browsers differ in the formats they supportNo changes to client sideServer-sideSimple file serverComplexity in recording functionMain advantages- No added infrastructure complexity
- Better quality on poor networks (assuming you have time to wait for the uploaded recording)
- Decoupling of recording requirements from client device characteristics and capabilities
- Full control over composited result
When would I record-and-upload?
I would go for client-side recording using MediaRecorder in the following scenarios:
- My sole purpose is to record and I am the only “participant”. Said differently – if I don’t record, there would be no need to send media anywhere
- The users are aware of the importance of the recording and are willing to “sacrifice” a bit of their flexibility for higher production quality
- The recorded stream is more important to me than whatever live interaction I am having – especially if there’s post production editing needed. This usually means podcasts recording and similar use cases
When would I upload-and-record?
Here’s when I’d use classic WebRTC architectures of upload-and-record:
- I lack any control over the user’s devices and behavior
- Recording is a small feature in a larger service. Think web meetings where recording is optional at the discretion of the users and used a small percentage of the time
- When sessions are long. In general, if the sessions can be longer than an hour, I’d prefer upload-and-record to record-and-upload. No good reason. Just a gut feeling that guides me here
How about both?
There’s also the option of doing both at the same time – recording and uploading and in parallel to upload-and-record. Confused?
Here’s where you will see this taking place:
- An application that focuses on the creation of recorded podcast-like content that gets edited
- One that is used for interviews where two or more people in different locations have a conversation, so they have to be connected via a media server for the actual conversation to take place
- Since there’s a media server, you can record in the server using the upload-and-record method
- Since you’re going to edit it in post production, you may want to have higher quality media source, so you upload-and-record as well
- You then offer these multiple resulting recordings to your user, to pick and choose what works best for him
If you are recording more than a single media source, let’s say a group of people speaking to each other, then you will have this dilemma to solve:
Will you be using WebRTC recording to get a single mixed stream out of the interaction or multiple streams – one per source or participant?
Assuming you are using an SFU as your media server AND going with the upload-and-record method, then what you have in your hands are separate media streams, each per source. Also, what you need is a kind of an MCU if you plan on recording as a single stream…
For each source you could couple their audio and video into a single media file (say .webm or .mp4), but should you instead mix all of the audio and video sources together into a single stream?
Using such a mixer means spending a lot of CPU and other resources for this process. The illustration below (from my Advanced WebRTC Architecture course) shows how that gets done for two users – you can deduce from there for more media sources:
The red blocks are the ones eating up on your CPU budget. Decoding, mixing and encoding are expensive operations, especially when an SFU is designed and implemented to avoid exactly such tasks.
Here’s how these two alternatives compare to each other:
Multiple streamsMixed streamOperationSave into a media fileDecode, mix and re-encodeResourcesMinimalHigh on CPU and memoryPlaybackCustomized, or each individual stream separatelySimpleMain advantages- No data loss from the session
- Can create multiple playback experiences
- Easy to diarize transcriptions since nothing is mixed
- Simple to implement
- Can mix later on if needed
- Simply to playback anywhere
- Requires less storage space
When would I use multi stream recording?
Multi stream can be viewed as a step towards mixed stream recording or as a destination of its own. Here’s when I’d pick it:
- When I need to be able to play back more than a single view of the session in different playback sessions
- If the percentage of times recorded sessions get played back is low – say 10% or lower. Why waste the added resources? (here I’d treat it is a step an optional mixed stream “destination”)
- When my customer might want to engage in post production editing. In such a case, giving him more streams with more options would be beneficial
When would I decide on mixed stream recording?
Mixed recording would be my go-to solution almost always. Usually because of these reasons:
- In most cases, users don’t want to wait or deal with hassles during the playback part
- Even if you choose multi stream for your WebRTC recording, you’ll almost always end up needing to provide also a mixed stream experience
- Playing back multi stream content requires writing a dedicated player (haven’t seen a properly functioning one yet)
What about mixed stream client side recording?
One thing that I’ve seen once or twice is an attempt to use a device browser to mix the streams for recording purposes. This might be doable, but quality is going to be degraded for both the actual user in the live session as well as in the recorded session.
I’d refrain from taking this route…
Switching or compositingIf you are aiming for a single stream recording, then the next dilemma you need to solve is the one between switching and compositing. Switching is the poor man’s choice, while compositing offers a richer “experience”.
What do I mean by that?
Audio is easy. You always need to mix the sources together. There isn’t much of a choice here.
For video though, the question is mostly what kind of a vantage point do you want to give that future viewer of yours. Switching means we’re going to show one person at a time – the one shouting the loudest. Compositing means we’re going to mix the video streams into a composite layout that shows some or all of the participants in the session.
Google Meet, for example, uses the switching method in its recordings, with a simple composite layout when screen sharing takes place (showing the presenter and his screen side by side, likely because it wasn’t too hard on the mixing CPU).
In a way, switching enables us to “get around” the complexity of single stream creation from multiple video sources:
SwitchingCompositingAudioMix all audio sourcesMix all audio sourcesVideoSelect single video at a time, based on active speaker detectionPick and combine multiple video streams togetherResourcesModerateHigh CPU and memory needsMain advantagesCost effectiveMore flexible in layouts and understanding of participants and what they visually did during the meetingWhen would I pick switching?
When the focus is the audio and not the video.
Let’s face it – most meetings are boring anyway. We’re more interested in what is being said in them, and even that can be an exaggeration (one of the reasons why AI is used for creation of meeting summaries and action items in some cases).
The only crux of the matter here, is that implementing switching might take slightly longer than compositing. In order to optimize for machine time in the recording process, we need to first invest in more development time. Bear that in mind.
When would compositing be my choice?
The moment the video experience is important. Webinars. Live events. Video podcasts.
Media that plan or want to apply post production editing to.
Or simply when the implementation is there and easier to get done.
I must say that in many cases that I’ve been involved with, switching could have been selected. Compositing was picked just because it was thought of as the better/more complete solution. Which begs the question – how can Google Meet get away with switching in 2024? (the answer is simple – it isn’t needed in a lot of use cases).
Rigid layouts or flexible layoutsAssuming you decided on compositing the multiple video streams into a single stream in your WebRTC recording, it is now time to decide on the layout to use.
You can go for a single rigid layout used for all (say tiles or presenter mode). You can go for a few layouts, with the ability to switch from one to the other based on context or some external “intervention”. You can also go for something way more flexible. I guess it all depends on the context of what you’re trying to achieve:
SingleRigidFlexibleConceptA single layout to rule them allHave 2, 3 or 7 specific layouts to choose fromAllow virtually any layout your users may wish to useMain advantages- Simple to implement
- Once implemented, it is hands-free
- Gives a few choices to your users
- Knowing the layouts in advance enables for code optimizations for them
- How to choose which layouts to have?
- When and how to switch between these layouts?
- How are layouts defined and created?
- When and how to switch between the layouts?
Here’s a good example of how this is done in StreamYard:
StreamYard gives 8 predefined different layouts a host can dynamically choose from, along with the ability to edit a layout or add new ones (the buttons at the bottom right corner of the screen).
When to aim for rigid layouts?
Here’s when I’ll go with rigid layouts:
- The recording is mostly an after-effect and not the “main course” of the interaction. For the most part, group meetings don’t need flexible layouts (no one cares enough anyway)
- My users aren’t creatives in nature, which brings us to the same point. The WebRTC recording itself is needed, but not for its visual aesthetics – mostly for its content
- When users won’t have the time or energy to pick and choose on their own
Here, make sure to figure out which layouts are best to use and how to automatically make the decision for the users (it might be that whatever the host layout is you record, or based on the current state of the meeting – with screen sharing, without, number of participants, etc).
When would flexibility be in my menu?
Flexibility will be what I’ll aim for if:
- My users care deeply about the end result (assume it has production value, such as uploading it to YouTube)
- This is a generic platform (CPaaS), and I am not sure who my users are, so some may likely need the extra flexibility
You decided to go for a composite video stream for your WebRTC recording? Great! Now how do you achieve that exactly?
For the most part, I’ve seen vendors pick up one of two approaches here – either build their own proprietary/custom transcoding pipeline – or use a headless browser as their compositor:
Transcoding pipelineBrowser engineUnderlying technologyUsually ffmpeg or gstreamerChrome (and ffmpeg)ConceptStitch the pipeline on your own from scratchAdd a headless browser in the cloud as a user to the meeting and capture the screen of that browserResourcesHighHigh, with higher memory requirements (due to Chrome)Main advantages- Less moving parts means the solution is more robust
- Cost effective, scales a bit better
- Easier to implement
- View can easily include any HTML/CSS element you desire
Here I won’t be giving an opinion about which one to use as I am not sure there’s an easy guideline. To make sure I am not leaving you half satisfied here, I am sharing a session Daily did at Kranky Geek in 2022, talking about their native transcoding pipeline:
Since that’s the alternative they took, look at it critically, trying to figure out what their challenges were, to create your own comparison table and making a decision on which path to take.
Live or “offline”Last but not least, decide if the recording process takes place online or post mortem – live or “offline”.
This is relevant when what you are trying to do is to have a composite single media stream out of the session being recorded. With WebRTC recording, you can decide to start off by just saving the media received by your SFU with a bit of metadata around it, and only later handle the actual compositing:
Live“offline”ConceptHandle recording on demand, as it is taking place. Usually, adding 0-5 seconds of delayUse job queues to handle the recording process itself, making the recorded media file available for playback minutes or hours after the session endedMain advantages- Can be used to stream the media to live platforms (YouTube Live, Twitch, LinkedIn Live, Facebook Live, etc)
- Better user experience (available faster)
- Better utilization of media processing resources
- Can be delayed until a request is made to playback a session
When to go live?
The simple answer here is when you need it:
- If you plan on streaming the composited media to a live streaming platform
- When all (or most) sessions end up being played back
When to use “offline”?
Going “offline” has its set of advantages:
- Cost effective – when you’re uncle scrooge
- Commit to compute resources with your cloud vendor and then queue such jobs to get better machine utilization
- You can use spot instances in the cloud to reduce on costs (you may need to retry when they get taken away)
- If the streams aren’t going to be viewed immediately
- Assuming streams are seldomly viewed at all, it might be best to composite them only on demand, with the assumption that storage costs less than compute (depends on how long you need to store these media files)
How about both?
Here are some suggestions of combinations of these approaches that might work well:
- Mix audio immediately, but wait up with video compositing (it might not be needed at all)
- Use offline, but have the option to bump priority and “go live” based on the session characteristics or when users seem to want to playback the file NOW
This has been long. Sorry about that.
Designing your WebRTC recording architecture isn’t simple once you dive into the details. Take the time to think of these requirements and understand the implications of the architecture decisions you make.
Oh, and did I mention there’s a set of courses for WebRTC developers available? Just go check them out at https://webrtccourse.com
The post WebRTC recording challenges and solutions appeared first on BlogGeek.me.
All the ways to send a video file over WebRTC
I am working on a personal Chrome Extension project where I need a way to convert a video file – like your standard mp4 – into a media stream, all within the browser. Adding a file as a src to a Video Element is easy enough. How hard could it be to convert a video […]
The post All the ways to send a video file over WebRTC appeared first on webrtcHacks.
Science fiction books that resonated with me
Some science fiction books I carry in my heart and mind wherever I go for quite a few years now. Consider it a condensed book review.
I am a sucker for science fiction books. About 15 years ago, when I had a blog on RADVISION’s website, I even wrote a post about how writers envisioned video conferencing in science fiction books. Alas, that post has died, along with the RADVISION blogs, years ago.
Last week I sat down in the car with my daughter, ending up talking about books. It dawned on me that there are several that have stuck with me throughout the years and resonated. Books that keep me thinking even today.
This time, I decided to share them here. Unrelated to WebRTC, video, CPaaS or communication technologies. Just something I wanted to share 🤷♂️
And yes. All links are affiliated – my Kindle needs a few new good science fiction books 😉
They’re brought here in no specific order (alphabetically…)
Table of contents- Blood Music / Greg Bear
- Daemon / Daniel Suarez
- Ender’s Game / Orson Scott Card
- Expendable / James Alan Gardner
- Old Man’s War / John Sclazi
- Ready player one / Ernest Cline
- The Peace War / Vernor Vinge
- The Speed of Dark / Elizabeth Moon
- Winter World / A.G. Riddle
- Wool / Hugh Howey
- Your turn
Greg Bear has many great books. Blood Music is definitely one of them (I had to decide if I suggest this one on Drawin’s Radio – ending up with this one).
What I like about this one is how it combines miniaturization with biology. I know nothing about biology and what I do know about technology and miniaturization is by using computers.
This was a compelling read and a really interesting one of what happens at the extreme ends of connecting the dots between these two things.
It also resonated with my own philosophical thoughts about the difference in depiction and scale between the makings of atoms to the whole universe. To understand this specific sentence, reading Blood Music by Greg Bear is likely needed.
Daemon / Daniel SuarezLLMs, chatbots, AI. This book has it all.
One of my previous managers suggested I read that, and he was spot on. It takes the angle of how the gaming industry and its NPCs (Non Player Characters) can make a difference if they are “let loose” in the world.
It takes the technologies we have today (or rather a few years ago) and tries to prophesize where we will be with them. Definitely a few misses in where we are headed, but a lot to think about.
Especially when the time to decide who works for who – the machine for us or us for the machine.
Go read Daemon by Daniel Suarez
Ender’s Game / Orson Scott CardThis is the second or third science fiction book I read in English and it got me onto the path of reading in English a lot. A roommate at the university gave it to me to read and said “it is about a small kid that saves the world”.
Besides the science fiction part of the book, how it covers bullying and the way to win in wars is interesting. I like how Orson outlines the story.
A few years after reading it, Orson Scott Card came to Israel for an event. I went there with a colleague from work for the book signing event, standing two hours in line for one minute with Orson. He gave me his full attention and was surprised at the book I brought to sign (Enchantment – it isn’t in this list since it is fantasy and not science fiction).
Anyway, Orson Scot Card is always a good read and Enter’s Game is a great starting point.
Expendable / James Alan GardnerThis is one enjoyable read. It took me into this riveting series of books by James Alan Gardner.
To put it short, explorers are expendable. They are dropped into new worlds to explore, and the reason they were selected is because they are deformed in one way or another but smart. So instead of fixing their external deformity (or ugliness), they are used as explorers. Why? Because if they looked good – they wouldn’t be expendable. Their death might matter to someone.
The rest of the series revolves around nanotech and AI. Or magic. Or something in between.
This is a lot less about ruminating about the books afterwards and more about enjoying the read – go read Expendable by James Alan Gardner.
Old Man’s War / John SclaziJohn Sclazi is another master storyteller (at least for me). Old Man’s War marks the beginning of a great series of many books (and not the only ones I love from John Sclazi).
Old Man’s War places humanity in a universe full of alien life – most of it warring in nature (or at least that’s the initial premise of it all). The way to build an army, the solution is to take the elderly and have them undergo a physical change, essentially taking them a bit apart from the rest of humanity and turning them into soldiers.
Since Earth is kept a wee bit back in its technology, they’ve seen most of what there is in life already and are old. So getting a younger body is all that is needed to recruit them for the cause.
The more I get older (age 40 was especially rough – it is when I started breaking in the seams or so it seems), the more I think about this series of books – and how I wish (or don’t wish) to be young again.
This series, as well as many of his other books are a joy to read – Old Man’s War by John Sclazi
Ready player one / Ernest ClineSkip the movie. Read the book.
This has the word metaverse all over it. If you read Snow Crash by Neal Sephenson then you’ll want to read this one. And if you haven’t then just go read them both 🤷♂️
Besides the part of metaverse, large corp and all that stuff we’re here to ponder, what really sets this book apart is the treasure trove that it is for nostalgy. If you are 40 years or older, know what a Commodore 64 is, played Pac Man on a handheld device before there was such a thing as a PC, then you’ll find your youth inside this book. For me, this was a true joy to read.
Oh, and I just started reading Ready Player Two (noticed that when I went searching for the books I loved for this article).
Go read Ready Player One by Ernest Cline.
The Peace War / Vernor VingeIf you know Vernor Vinge as a scifi writer then you don’t need me for this one. If you read scifi and haven’t read a Vernor Vinge book then you should. In such a case, The Peace War is a great place to start.
This one is about technology and fighting wars with the resources you have. Where one side rules all the other goes and miniaturizes stuff.
This, as well as many of his other books just float in my head and come out from time to time (especially books like A Fire Upon The Deep or Rainbows End, both from the point of view of communication technologies and artificial intelligence).
Anyways, just go read The Peace War by Vernor Vinge. Or any other book by Vernor Vinge for that matter…
The Speed of Dark / Elizabeth MoonThis book touched me in many ways. It isn’t exactly science fiction – it is mostly the effect improvements in healthcare on moral decisions we need to take.
In this case, it is about the last autistic people in the world, after autism is all but eradicated, and what it means for an autistic adult to decide to “heal”. Would that be a good thing for him? A bad one? Will he stay the same person?
And all of that written from the point of view of the autistic person.
I truly loved this one and walked around with the baggage it left in me afterwards. Highly recommended – The Speed of Dark / Elizabeth Moon.
Winter World / A.G. RiddleI read this one last winter… and it got me into the mood of winter and kept me there. All dark and cold. This book (and the series) is so well written. You can just feel the cold and the darkness as you read it.
The story is about our earth, dealing with climate change – one where the sun just gets blotted out of the sky until it is no more visible. At least that’s the first book. It is about choices – technological and human ones. And about our will to survive.
I’ll just leave it at that and say that this winter here is cold as well. And it got me thinking about this book series again.
Go read Winter World by A.G Riddle.
Wool / Hugh HoweyNo. I haven’t seen it on Apple TV. I read the book and then all 3 books in this series. And then the rest of the Silo stories available. It is that riveting.
This is less about technology (at least the first book) and more about the human condition and how technology affects it. Like many of the other books in this article that I am recommending, this series is also dystopian in nature. It isn’t that I like my books bleak – it is just that the bleak ones stick with me longer and cause me to think about my day to day a lot more.
Anyways, go read Wool by Hugh Howey.
Your turnGot any books you think I should be reading? Science fiction and fantasy would be great:
- For fantasy more single book experiences (think Enchantment by Orson Scott Card or Neverwhere by Neil Gaiman)
- For Science fiction I am quite comfortable with series of books
Now I need to get back to Ready Player Two 😉
I’ll be back to the usual communication technology articles next time.
The post Science fiction books that resonated with me appeared first on BlogGeek.me.
An FAQ for WebRTC beginners
Answering some common FAQ questions about WebRTC that seem to be top of mind on Google search.
A few days ago, I searched something on Google, and somehow bumped into a page full of questions Google found relevant or common. These weren’t exactly relevant to my search term (not directly), but they were there. And they were beginner questions about WebRTC.
It dawned on me that I’ve probably mentioned some of these things in passing (or a wee bit more) in the past, but placing them all neatly together in one place made sense. So here we are. And here’s the WebRTC FAQ for beginners.
Table of contents- Is WebRTC TCP or UDP?
- Is WebRTC still used?
- Is WebRTC free or paid?
- What is WebRTC used for?
- Is WebRTC a security risk?
- Does Netflix use WebRTC?
- Can WebRTC be hacked?
- Does WebRTC expose your IP?
- What is better than WebRTC?
- Is WebRTC better than Websockets?
- Is Google a WebRTC?
- Does WebRTC need a server?
- Does WebRTC require Internet?
- Does WebRTC use SSL?
- Where’s the answer to my question?
WebRTC is neither TCP nor UDP. At the same time WebRTC is both TCP and UDP.
Confused?
Let’s put things in order.
With WebRTC there’s signaling and media.
Signaling is considered to be out of scope and left to the application. Most applications will use HTTPS or a secure WebSocket as transport for signaling. HTTPS runs over TCP… sort of… since HTTP/3 can also do UDP. But mostly, you can think of signaling in WebRTC as TCP and the skies won’t fall ( what we want for signaling is reliability and messages order, and TCP based protocols give us that).
Media in WebRTC wants to use UDP. It strives to use UDP as much as possible, but that’s not always available to it, so it then falls back towards using TCP. But you can consider this as a last resort (we don’t want to be in that predicament).
Read more about WebRTC transport:
- We TURNed to see a STUNning view of the ICE
- Why you should prefer UDP over TCP for your WebRTC sessions
Yes. You wouldn’t be reading my blog otherwise
It isn’t that there aren’t any challengers. It is that WebRTC is still the most popular and common solution for real time communications in web browsers.
WebTransport + WebCodecs + WebAssembly might someday replace WebRTC. But we’re not there yet.
Read more about WebRTC’s success and future:
- WebRTC unbundling: the beginning of the end for WebRTC?
- Can a native media engine beat WebRTC’s performance?
- WHIP & WHEP: Is WebRTC the future of live streaming?
Free. Err. Paid. Free? Paid? Both? None?
Let’s sort things out here.
WebRTC is an open standard with a popular open source implementation maintained by Google and used by all major browser vendors.
Accessing the APIs and using them is free.
But creating most of the meaningful applications is going to require some sort of payment. That can be to a CPaaS vendor to host the WebRTC infrastructure; or to an IaaS vendor (think AWS) to host the servers and the bandwidth use (especially with TURN and media servers).
So yes. WebRTC is free, but expect to pay for it, in particular if you need help. Google will not help you…
Read more about WebRTC’s costs:
- Is WebRTC really free? The costs of running a WebRTC application
- WebRTC is FREE. But Developers Aren’t
- Why Doesn’t Google Provide a Free TURN Server?
- WebRTC reduced barriers and increased innovation in communications
WebRTC is used for implementing realtime voice and video communications over the internet using web browsers. But it definitely isn’t limited to that.
I’ve seen use cases dealing with recording, live streaming, broadcasting, cloud gaming, remote teleoperation (that’s driving a car… remotely), peer assisted delivery, file transfer, … the list is endless.
Read more about WebRTC use cases:
- WebRTC reduced barriers and increased innovation in communications
- 10 Massive Applications Using WebRTC
- Fitting WebRTC in the brave new world of webcams, security, surveillance and visual intelligence
- Zooming in on remote education and WebRTC
- WebRTC in telehealth: More than just HIPAA compliance
- Cloud gaming, virtual desktops and WebRTC
- WHIP & WHEP: Is WebRTC the future of live streaming?
- 7 Creative Uses of WebRTC’s Data Channel
WebRTC enables browsers to have (and give) access to your microphone, camera, display and IP address. This is what every voice or video meeting application you install requires in order to work properly as well.
Is that a security risk? That’s up to you to decide as a user.
Giving such power to the browser reduces the friction for users but also for nefarious third parties who want to exploit these capabilities, so some will see this as an increase in security risk.
For developers it simply means that they need to know and understand what they are doing and how they implement their applications with this technology in order to mitigate any potential risk. It is worth noting that WebRTC and web browsers from their side do the most they can to reduce such security risks and even encourage developers to write secure applications.
Read more about WebRTC security:
Does Netflix use WebRTC?No.
Netflix might be using WebRTC somewhere, but for its main video streaming service Netflix doesn’t use WebRTC.
Why? Because WebRTC is designed and fine tuned for real time communications. As such, it sacrifices quality for improved latency.
Netflix is the exact opposite. It strives to deliver the best quality and is willing to sacrifice a bit of latency while at it – you wouldn’t mind waiting a few seconds for your movie to start in order to have crisp and pristine video. On the other hand, you’d be pissed if your online video conversation had a latency of 5 seconds and felt as if the other person was sitting on the moon.
Read more about WebRTC and latency:
- With media delivery, you can optimize for quality or latency. Not both
- Why you should prefer UDP over TCP for your WebRTC sessions
- WHIP & WHEP: Is WebRTC the future of live streaming?
Yes.
Everything can be hacked.
Browsers are trying to do their best to reduce that risk for WebRTC (and other technologies they implement), but it is an arms race…
Read more about WebRTC security:
Does WebRTC expose your IP?This is a tricky question. The answer is yes and no.
Let’s start by understanding which IP address…
Your device usually has two IP addresses:
- A local IP address, used inside its local network – say the home network
- A public IP address, which the NAT assigns to it and is used to communicate with “the world”
Each application on your device, including the browser, has access to the local IP address.
Each web server you connect to on the internet sees your public IP address.
When negotiating a WebRTC session, WebRTC uses a mechanism called ICE which discovers your public IP address and shares your local and public IP address with the peer it connects with.
A few quick clarifications here:
- WebRTC will not expose a local IP address without permissions to access a camera or a microphone
- Any voice or video communication applications ends up exposing the same addresses in similar fashion
- A WebRTC application can decide to use only TURN relay or media servers so as to not expose these IP addresses to other users
- There are browser extensions that can be used that limits the ability to expose local IP addresses
- If your VPN leaks your public IP with WebRTC it is that VPN which is not working
More about WebRTC IP leak:
- What is the WebRTC leak test? [Guide]
- PSA: mDNS and .local ICE candidates are coming
- Everything you need to know about WebRTC security
A cheesecake is definitely better than WebRTC. A chocolate cheesecake is doubly so.
In all seriousness though, I have no clue.
It depends. Which is a cop out answer but the only one here.
The question should be more specific. It should include what it is you are trying to build, what is the target audience and what medium do you want to use for it.
For live streaming, WebRTC might not be the best fit. Especially if you can live with a 2 seconds delay (in that case, LL-HLS and LL-DASH would be better solutions for example).
For video conferencing… well… I’d start by selecting WebRTC by default. And then try to poke holes in my decision and select something else – proprietary – since there is nothing else…
More about WebRTC alternatives:
- WebRTC is a technology not a solution
- Can a native media engine beat WebRTC’s performance?
- WHIP & WHEP: Is WebRTC the future of live streaming?
{kind=link}
Apples to oranges.
I’d use both. In the same application. Seriously.
WebSocket for signaling and WebRTC for media.
There are two places where you can think of WebRTC and WebSocket as alternatives:
- WebRTC’s data channel, which is bidirectional in nature and peer-to-peer. For the most part, I’ll still use WebSocket. Unless I am serious about my low latency requirements or my privacy requirements
- When aiming for live streaming. But then I might just go for WebTransport instead of WebSocket – being forward thinking…
Did I already say apples to oranges?
More about transport in WebRTC:
- WebRTC Signaling Protocols and WebRTC Transport Protocols Demystified
- Who Needs WebSockets in an HTTP/2 World?
- WHIP & WHEP: Is WebRTC the future of live streaming?
To be frank – Google is Google. Not sure what the question is here
Google and WebRTC have an interesting relationship.
It all started when Google acquired GIPS, a company who licensed media engines. A bit afterward, WebRTC was announced in the standardization organizations and Google made the GIPS media engine into an open source implementation, integrating it into Chrome and placing APIs on top of it – these APIs were the WebRTC API specifications (or close enough at the time).
That was over 10 years ago. Since then, WebRTC has evolved and so has Google’s implementation of it.
Google uses WebRTC internally for Google Meet and for other products and projects it has.
The actual WebRTC project is open source. Maintained by Google. And most of the contributions to it are Google’s.
More about WebRTC & Google:
- The Death of Signaling as we Know it
- With WebRTC, better stick as close as possible to the requirements, architecture and implementation of Google Meet
- With WebRTC, don’t expect Google to be your personal outsourcing vendor
- My WebRTC predictions for 2024
Yes. WebRTC needs a server. In fact, it needs multiple servers.
For starters, you need to download the application logic from somewhere, and a way to signal who you want to make a conversation with. This is done with a signaling server.
Then, when connecting the WebRTC session, there are times when you won’t have a direct route for the media. In such cases, you are going to need a TURN server. TURN servers also act as STUN servers but STUN servers are not the same as signaling servers.
And, you may want to go fancy – run a group meeting, record stuff. Such capabilities almost always mean you are adding a media server into the mix.
Read more about WebRTC servers:
Does WebRTC require Internet?Yes.
Everything today requires the Internet. Even you being able to read this FAQ requires the Internet.
WebRTC can run in local networks or private networks without connecting to the public Internet. But it still needs an IP network to work.
Does WebRTC use SSL?Yes.
Let’s start with definitions first: For me SSL and TLS are one and the same.
HTTPS and WSS (Secure HTTP and Secure WebSocket) both run on top of TLS so they are also → SSL.
Web browsers practically force application developers to use HTTPS for the pages that host these services, which means all signaling used with WebRTC will be done via HTTPS or WSS.
The media uses SRTP, which is Secure RTP, which doesn’t use TLS (because it isn’t running over TCP). That said, when sessions need to be relayed via TURN servers, they might end up being relayed over TURN/TLS.
Read more about WebRTC security:
- WebRTC is the most secure VoIP protocol
- Why you should prefer UDP over TCP for your WebRTC sessions
- Everything you need to know about WebRTC security
Couldn’t find the answer?
I can invite you to follow and read my blog – it has a lot of resources about WebRTC
My suggestion? Start here What is WebRTC?
If you are looking to skill up with WebRTC, I also have WebRTC courses for you.
The post An FAQ for WebRTC beginners appeared first on BlogGeek.me.
My WebRTC predictions for 2024
Here are the WebRTC trends and predictions you should expect in 2024. They are a continuation of what we’ve seen in 2023 with a few variations.
Time to look at what we’ve accomplished in 2023 and think what’s ahead of us in 2024 when it comes to WebRTC.
When we look ahead, there are several notable things that glare at us immediately:
- WebRTC is here to stay. But in some cases and for some use cases, the focus is shifting towards WebTransport+WebCodecs+WebAssembly
- The recession is here and it isn’t going anywhere, so a continuation of what we’ve seen a year ago
- Generative AI is getting all the love and attention out there. It is also finding its way slowly into WebRTC services
Last year, I became CPO at Spearline. This year, Spearline got acquired by Cyara and I am now Senior Director of Product Management there. I am still delving into WebRTC and CPaaS. Still consulting a bit here and there on these subjects when it makes sense.
If you are interested, you can read my last year’s WebRTC predictions for 2023
Let’s get started here…
Table of contents- The video version
- The era of differentiation in WebRTC
- What does WebRTC use look like?
- WebRTC, open source and XaaS
- How did I do with my 2023 WebRTC predictions?
- WebRTC predictions for 2024
- 2024, here we come
This year, I took the liberty of also sharing my predictions in a video form. It holds the essence of my WebRTC predictions for 2024, in a short form.
Read on below to get into the details.
The era of differentiation in WebRTCWe are well into the era of differentiation:
I’ve had this slide done somewhere in 2020, modifying it a bit to fit the pandemic.
It is as relevant today as it was last year:
- We started off with WebRTC in an exploratory fashion, asking ourselves should we even use this technology?
- Then we saw a growth spurt, where it was obvious WebRTC is here to stay. The question changed to how do we use it
- That got us right into the age of differentiation, where services from different companies look so alike, using the same WebRTC interface and capabilities, that we now ask ourselves how do we compete
The answers of how we compete varies on a yearly basis. Now, it obviously revolves around generative AI and LLMs. That’s the easy answer. The truth is a lot more complicated and nuanced. It requires understanding where investments are currently made – both at Google and in the ecosystem around WebRTC and its use.
What does WebRTC use look like?Last year I predicted usage would be 3 times higher than pre-pandemic. That meant lowering the use at the beginning of 2023 from 4 times to 3 times pre-pandemic. The end result? We stayed at around 4 times pre-pandemic usage.
From here, it can only go up, though slowly and linearly but likely after 2024:
- New use cases are unlikely to cause people to start doing more video calls
- Growth ahead will come from shifting on premise solutions to cloud ones and at the same time, migrating to WebRTC use
I am not going to touch the topic of open source here. I’ve done that in my article two weeks ago writing about the top WebRTC open source media servers on github.
XaaS requires a few words of explanation, and I am likely to cover them in the coming months in further detail in a separate article.
For me, XaaS is IaaS, CPaaS and SaaS. In all cases, it is a matter of looking at them from the prism of WebRTC APIs CPaaS.
CPaaSThe landscape is changing in the CPaaS domain. A few years back, the leading vendors for WebRTC APIs were Vonage, Twilio and Agora. Probably in this order.
Here’s what I had to say in my last year predictions article:
The perceived leaders in WebRTC CPaaS are still Twilio, Vonage and Agora. I have a feeling that by the end of 2023 this will change.
Little did I know this would be spot on…
Twilio just announced in December that it is exiting the video business altogether. They still have and use WebRTC for their voice capabilities, mainly with a focus on call centers. But other than that? They just became irrelevant to many developers.
Most vendors are now likely to want to compare themselves now to Vonage and Amazon Chime SDK. Agora probably as well.
From a perspective of innovation or specific market niches, other vendors come to mind as solid alternatives here. Companies such as Daily and Dolby for example (there are others – sorry for not mentioning everyone). Or LiveKit with its open source alternative.
Notables?
- Twilio all but left the market a year ago, shifting focus to voice and text contact centers and CDPs. In December 2024 they announced sunsetting Twilio Programmable Video service
- Vonage has been working on integrating machine learning pipelines into their SDKs, which is great
- Dolby doubled down on low latency streaming and high end audio requirements
- Daily leads in lowcode efforts and has been putting a lot of attention in the past year towards AI and partnerships
- Agora has just released a signaling SDK and introduced VP9 support
That change at Twilio places more strain on developers who need to choose who to use, with the added new risk of the level of commitment they see in the CPaaS vendor they choose. When someone like Twilio throws you under the bus, what can you expect from other vendors?
SaaSSaaS vendors are vying towards CPaaS, assuming for some unknown reason that there’s money to be had from developers.
There are a few that are taking this route.
The problem that I see here is the fact that Twilio decided this isn’t interesting enough. While they have the APIs – they don’t invest in it any further. Meaning it isn’t a big enough market for Twilio. In such an atmosphere, how would it be big enough for SaaS vendors, and how will they see the explosion in use of their infrastructure that they likely haven’t seen in SaaS.
Some of them may yet succeed, but the path here isn’t an obvious or a simple one.
IaaSAmazon, Microsoft, Google… and… Cloudflare.
- Amazon has AWS Chime SDK
- Microsoft has Azure Communication Services
- Google has… nothing
- Cloudflare introduced WebRTC services throughout 2023
Let’s see where that takes us
Amazon is investing in Chime SDK. Especially when it comes to audio quality and capabilities. In many ways, Amazon is shifting the attention of developers from CPaaS to their Chime SDK as a solid alternative. This is a trend that should be watched by CPaaS vendors and developers alike.
Microsoft seems content with their current offering of Azure Communication Services. There were no new or interesting announcements around it in 2023, which begs the question – is it important enough for Microsoft and a viable solution for developers?
Google announced APIs for Google Meet. Ones that integrate with it, but not ones that use its infrastructure for me to build my own video experiences. So no luck there for a CPaaS play. Time will tell if this changes. It is unlikely to happen in 2024.
Cloudflare entered the market with much fanfare. I covered them in 2023’s predictions. Since then, there have been no material announcements. Is that good? Bad? I just don’t know.
How did I do with my 2023 WebRTC predictions?I spent quite a lot of time on my predictions in 2023. Let’s see how well I did.
#1 – libWebRTC (and the future of WebRTC)I’ve made the prediction that Google’s WebRTC library will focus on house cleaning, optimizing and polishing collaboration. It did all that this year. We see this on an ongoing basis in our WebRTC Insights service.
What was interesting to note, is a slight shift towards requirements coming outside of Google Meet. There’s work being done to include H.265 support in libWebRTC, wherever H.265 is available in a hardware implementation form (i.e – someone is already paying the patent royalties bill).
Is that because Google was benevolent and nice? Is it because they wanted to show they aren’t a monopoly in Chrome? Is it because of some other deal with Intel (the ones pushing H.265 into WebRTC). Or is it simply because they might end up using it in Google Meet in all-Apple devices meetings? Time will tell.
#2 – Machine learning and media processingI assumed that WebAssembly would continue to be used with WebRTC for media processing in things like background replacement, noise suppression and proprietary codecs implementations.
It was.
Some of it was done in WebAssembly and browser level. A lot of it was relegated to the cloud or kept in native applications. What I found interesting, that some vendors chose to announce and release such solutions across all platforms and not start from native and move towards the web later.
Most interesting (and obvious) change here? A lot of this use is now being remarketed as generative AI – doesn’t matter if it is generative or not.
#3 – Voice before video (Lyra first, AV1 later)I thought Lyra (=new voice codec) would find its way to applications faster than AV1 (=new video codec). Or at least new voice codecs…
The results are… inconclusive.
Webex did come out with a new Webex AI audio codec, with little explanation about it.
AV1 is starting to make real noises of almost-maturity, with Apple supporting AV1 hardware acceleration (for decoding only at the moment) and Google fiddling around with AV1 in Google Meet.
We didn’t hear much this year about Google’s Lyra or Microsoft’s Satin codecs. Just this new announcement of the new Webex AI codec. So I am not sure if voice happened before video or not.
#4 – ObservabilityYes. There is more interest in observability. I know that by looking at our numbers in testRTC. There is no specific market or industry where it happens more. What I can say is that many contact centers are starting to take note. Probably due to their increased reliance in WebRTC and the fact that many contact center agents are working from home now.
#5 – M&As and shutdownsWe had a few interesting shutdowns and M&As. The most notable ones?
- Omegle shutdown
- Verizon closing Bluejeans
- Hopin got split, selling “Hopin” to RingCentral, keeping StreamYard
- Twilio shutting down Twilio Programmable Video – and then Jeff Lawson becoming Twilio ex-CEO
- Spearline was acquired by Cyara. Not necessarily because of WebRTC, but still
A lot of WebRTC engineers found themselves a new home. Either because their startups shut down, their company downsized or they saw no future where they were.
Good talent is there to be had if you look hard enough.
WebRTC predictions for 2024Enough about 2023. That’s old news. Lets see what’s going to happen with WebRTC in 2024
#1 – libWebRTC (and the future of WebRTC)I’ll start with the most important piece of our technology puzzle – libWebRTC, maintained by Google.
This year will be a continuation of last year. Mostly maintenance releases, with a few minor improvements. The places where we will see the most amount of focus by Google in libWebRTC:
- Access to media frames, raw and encoded, via Insertable Streams. This will include optimizations and a bit more flexibility. The purpose of it all is to promote and push forward AI capabilities
- Collaboration. A continuation of last year. Some of it via Insertable Streams. Others through polishing of media control APIs in the browser to enhance the user experience
- Accommodating AV1. I believe by the end of 2024, we will finally see Google Meet using AV1 – we’ve just seen a glimpse of that. In some limited scenarios, on select device types. There’s also work being done to allow for VP9 simulcast with hardware acceleration instead of using VP9 SVC
- Voice AI. Google will put Lyra or similar into Google Meet itself. Either as a standalone or by somehow plugging it into Opus or similar. Maybe it will do so via Insertable Streams, but I doubt this will be the route they will take here
By the end of 2024, we will find ourselves similar to where we are at the beginning of it:
- Google will be the main and virtually sole contributor to libWebRTC. The total commit numbers have been dwindling and this will continue. Will we see it stabilize in 2024?
- Here and there, external contributions will happen. Most of them are likely to come with Philipp Hancke. But here as well, we’ve probably seen the peak of individual contributions already…
WebAssembly is where we see innovation and differentiation in WebRTC. 2024 will be no different.
It will be incorporated in the “same old places” of media processing.
What we will see is also a lot more machine learning on the server side, and a lot of it will be leaning towards generative AI and LLM technologies. This isn’t really a prediction, but just stating the obvious here. For someone who uses Midjourney for many of his recent articles for imagery, that shouldn’t seem as a surprise to you.
#3 – The year of Lyra and AV1Time to take a huge risk.
I mentioned this in the libWebRTC prediction, but it deserves a section of its own as well.
Each year I say AV1 is years away. I think it is still going to take time until it becomes commonplace. That said, I believe this year we will see AV1 in one or more commercial WebRTC services, including Google Meet. It will be used judiciously and in very specific use cases and scenarios – call this testing the water.
On the audio side, we will see an AI audio codec being used in production in web browsers. Likely from Google. I believe Lyra will find its way into Google Meet. How exactly is where I am uncertain.
#4 – WebTransport as a real alternativeWebTransport started life somewhere in 2020. We’re now at the beginning of 2024.
It still isn’t available in all browsers – Safari is still missing support for it. It is available elsewhere, but far from being commonly used or in the mainstream’s mindset.
We’ve seen this year a few more experiments and proof of concepts with WebTransport that incorporate low latency media delivery. Mostly in the domain of streaming. There are reasons for that. I’ve written about that when discussing WHIP and WHEP.
Here’s what I think is going to happen: in 2024, we will see the first production ready low latency streaming solution that makes use of WebTransport instead of WebRTC or other technologies. This will be for one-way large scale broadcast use cases, where 1-2 seconds of latency are fine.
There will be those that will use WebTransport for bidirectional media delivery, similar to what Zoom is doing in web browsers, though that will stay the exception of the rule and more of an experimentation.
#5 – M&As and shutdownsThis was easy in 2023 and will remain easy in 2024.
The recession is here. It is likely to stay throughout 2024, with no real end in sight. At least not yet.
More vendors relying on WebRTC will shut down. Small startups will run out of steam. Large vendors may decide to exit this market and focus on other avenues where they conduct business.
Shutting down may mean getting acqui-hired, or acquired for peanuts. It might also mean selling chunks of the business to another company.
Vendors who stick to this market are likely to slow down their efforts throughout the year in an attempt to survive and weather this ongoing storm.
2024, here we comeLots to do in 2024, but with limited resources:
- Slowdown at the same time we see technology shifts and the need to differentiate
- Generative AI, and AI in general and trying to figure out where it fits in WebRTC use cases
- Polishing collaboration and sharing capabilities in WebRTC and getting that implemented in apps
- Introducing next generation audio and video codecs
- Researching new transport technologies
All that while trying to satiate users and customers with new features and releases.
The post My WebRTC predictions for 2024 appeared first on BlogGeek.me.
Top WebRTC open source media servers on github for 2024
What are the WebRTC open source media servers in 2024, and which ones are the best, based on github stars.
This one is one of those sensitive articles which many people later complain about. So I’ll start it with a few disclaimers:
- Different tools are suitable for different use cases. This means that a WebRTC media server here that is low on the popularity list might be the best fit for your requirements
- It was enjoyable to look it up, so I just had to write this down
- I love you all – I truly do. Please don’t be mad at me
- That said, I am expecting a sarcastic enough meme by Iñaki. One that I can proudly add to this article – just below this bullet
- The WebRTC open source ecosystem
- My “top 4” WebRTC open source media servers
- Using github for our WebRTC popularity contest
- Janus
- Jitsi Meet
- Mediasoup
- Pion
- The best WebRTC open source media server
WebRTC is free. At least the part of it being an open standard with a commercial grade open source implementation that is available and embedded across all modern browsers.
This has garnered a nice developer ecosystem around it, part of which is open source in its nature. A simple search for “webrtc” on github returns over 32k results.
There are a lot of different avenues to WebRTC projects on github. The main ones that come to the top of my head include:
- Media servers
- Signaling servers and frameworks
- WebRTC implementations in different languages
- Samples and experiments
- Applications written on top of WebRTC
- …
For this specific article, I want to focus on media servers.
My “top 4” WebRTC open source media serversThere are quite a few WebRTC media servers, many of which are open source. That said, most aren’t widely known or got to the point of being interesting enough for me to take notice (I usually take notice when someone tells me he is using it for something that goes to commercial use).
Throughout the years, the list of the popular WebRTC media servers hasn’t changed that much. I’ve been using this diagram for two years now, and it probably still holds true:
Due to this, my “top 4” is simply the WebRTC open source media servers above that are still relevant. And to make sure people don’t bash me on minor issues, I’ll be presenting my these in their dictionary order: Janus, Jitsi, mediasoup and Pion
Using github for our WebRTC popularity contestHow do you even begin deciding which WebRTC open source media server project is the most commonly used out there?
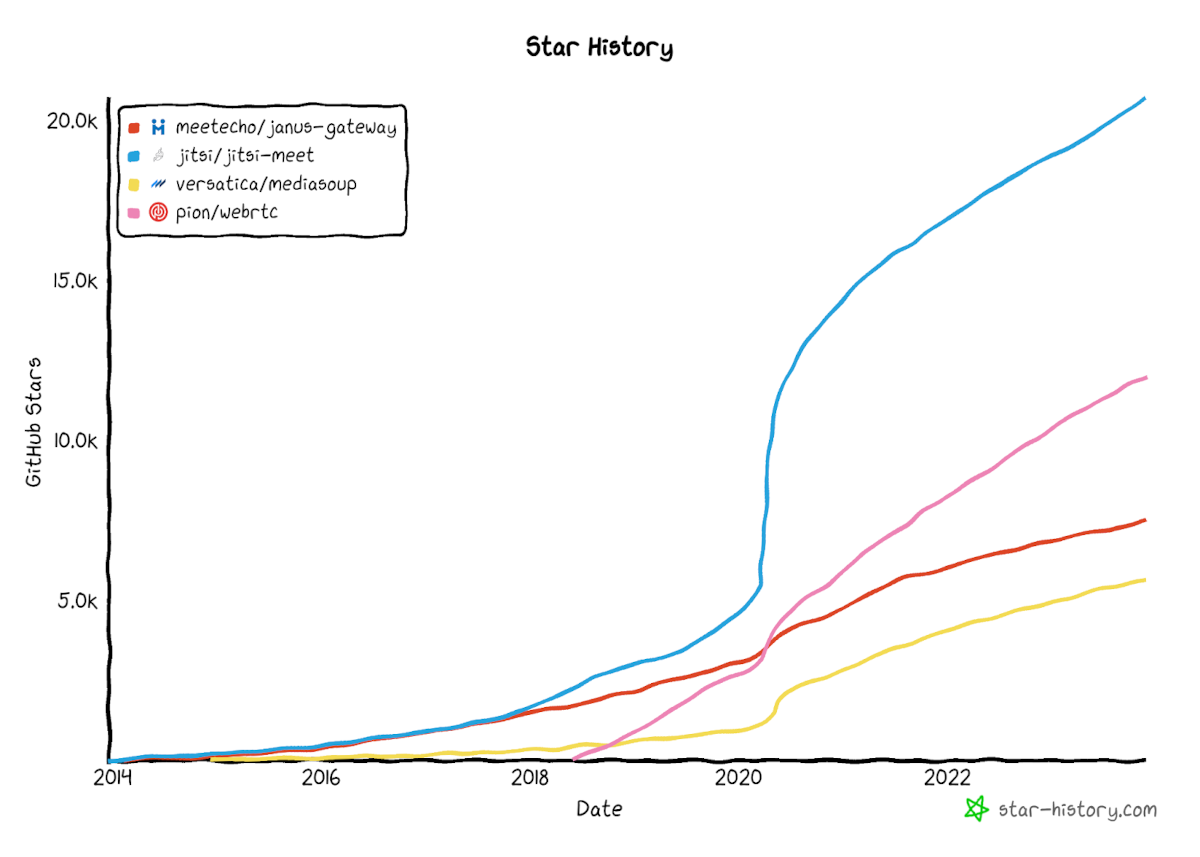
One approach is to count the stars. Github starts. Luckily, all the projects I was interested in have github repos. Philipp Hancke directed me to GitHub Star History, which after a bit of fooling around with, got me this nice initial chart:
{kind=link}
Based on people who placed a star on these github projects, we can see that mediasoup is chugging along, last in the packet. It is followed by Janus. Then there’s Pion and Jitsi Meet is ahead of the pack.
Each of these projects started at a different point in time. Pion was last to the party, which means the other projects had a headstart on it. Aligning them all on the point in time they were added to github, produces this chart:
Initial immediate thoughts here?
- mediasoup is the slowest growing media server
- Janus is growing at a steady, albeit slow pace
- Jitsi changed its trajectory during the pandemic and growing faster ever since
- Pion is the fastest growing project here, keeping at Jitsi’s recent pace to stardom
Let’s do a quick deep dive into each one of these.
JanusJanus is one of the oldest WebRTC media servers. It is written in C, which might be the reason for its limited adoption – most developers these days won’t know how to write a hello world application in C – let alone figure out its memory use concepts (where you have to explicitly free what you allocate).
What Janus has going for it is a company. Meetecho, the maintainer of Janus, offers paid support and development services around Janus. Something other open source WebRTC media servers lack.
The trajectory of Janus is unlikely to change. It is versatile, has a community around it and support services.
Jitsi MeetJitsi Meet is likely the oldest of WebRTC media servers. Started by Bluejimp, who were acquired by Atlassian and then 8×8.
While Jitsi doesn’t offer any direct support and development services for Jitsi, it does offer JaaS – a managed Jitsi service for developers.
Jitsi is written in Java and has a React UI implementation.
One reason for its meteoric rise is the pandemic. Jitsi is the only open source solution that came fully built and optimized for group calls. From the get go, their mission was to build an open source Google Hangouts (that’s Google Meet today). And they succeeded.
By narrowing their applicability to a specific use case, they opened up their viability as a solution to a larger target audience – way beyond that of developers building applications.
This unfair advantage places them here as a top dog. This doesn’t mean that they are suitable for everyone – quite the opposite. They are suitable for those building Google Meet-like experiences. For things that are beyond this use case, shop around the other media servers first. But for a Google Meet-like service? Start from Jitsi Meet.
MediasoupMediasoup is the Node.js implementation of an open source WebRTC media server. It is designed for high performance, with the unique concept of having the application built right inside the same Node.js process.
The challenge with mediasoup is its inability to offer official support and development services. Here, the reason is simple – the main creators and contributors work as developers at Miro today.
This challenge is probably what led to the slow growth of mediasoup in the github popularity contest.
That said, if you go and look at many large scale group calling deployments, they use mediasoup…
PionPion is last to the scene, but fast growing compared to the others. There are 3 reasons why:
- Pion is written in Go language. For some reason, Go has its fandom of developers who love the language. This makes Pion their Go-to (pun intended) open source project
- Pion is general purpose. It is used to build both clients and servers. There are multiple media server implementations written on top of Pion, but in general, the fact that you can build more with it garners immediately more stars to the project
- Sean DuBois. The person who started Pion has a huge and infectious personality that helped push Pion forward. Other open source projects have their own unique personas, but whoever had the chance to speak with Sean directly will understand what I am saying here
As Pion’s popularity grows, so are the number of commercial services cropping up that use Pion.
The best WebRTC open source media serverNone.
All.
It depends.
For managers, my suggestion is almost always to let their developers experiment and pick and choose the open source WebRTC media server that they see fit. There are differences across these alternatives, but at the end of the day, if anyone tries to force a developer to use something he doesn’t think is the right solution – said developer will make sure to explain to the one forcing him why the decision made is the wrong one. In other words, you don’t want to go against your developers.
For developers, I find myself suggesting different media servers depending on their use case, requirements and even company DNA.
So in short, there’s no best WebRTC open source media server. There are several alternatives that are great – you just need to pick the one that is best for you
The post Top WebRTC open source media servers on github for 2024 appeared first on BlogGeek.me.
The Hidden AV1 Gift in Google Meet
Earlier last week a friend at Google reached out to me asking Does Meet do anything weird with scalabilityMode? Apparently, I am the go-to when it comes to Google Meet behaving weirdly :). Well, I do have a decade of history observing Meet’s implementation, so this makes some sense! It turned out that this was […]
The post The Hidden AV1 Gift in Google Meet appeared first on webrtcHacks.
Twilio exits video APIs, further focusing on voice, SMS and Segment
Twilio Programmable Video is no more. What should WebRTC Video API vendors and their customers do from here on?
This week, Twilio dropped a bombshell
It decided to shut down its Programmable Video service and do a bit of downsizing and trimming around Segment and Flex.
I didn’t intend to write anything more until 2024, but this necessitated changing my plans.
The image above is an adaptation from a blog post on Twilio’s website from 2021…
Table of contents- Twilio Signal, and why I stopped covering it
- CPaaS vendors: Best of breed vs best of suite
- The cases of Twilio IOT and Twilio Live
- The demise of Twilio Programmable Video
- Innovations in Video APIs and WebRTC managed services
- The rise of the Zoom Video SDK
- The future of managed Video APIs (without Twilio)
- Where should Twilio Video customers go from here?
Each year, Twilio hosts its Twilio Signal event. I’ve attended a couple of them in person and used to cover them here on a yearly basis.
That stopped with Twilio Signal 2021, which was the last time I covered that event here. The reason for that was the pivot Twilio made from CPaaS to CEP (Customer Engagement Platform).
Ever since, I’ve searched for things to talk about and share about Twilio Signal, but found nothing of real value or interest to my readers.
Remember – I cover WebRTC and CPaaS. CPaaS mainly from the point of view of WebRTC and modern communications and less from the SMS and legacy telephony sides of it.
The shift towards CEP meant a lot less investment and focus by Twilio on exactly these areas – WebRTC and CPaaS that are non-SMS/legacy telephony related.
What did Twilio have to show for its investment in video and WebRTC in 2022 and 2023? Nothing. Crickets. Oh… yes… they did integrate with Krisp for noise cancellation. Presumably only in their Video SDK and not the Voice SDK. So that’s down the drain as well.
The decision might be the right one for Twilio, if you look at where their investments and attention are going:
- Twilio Flex, for a programmable contact center
- Segment, as a leading CDP vendor
- Fuzing Segment with programmable communications
Video is likely 1% or less of their revenue. So why bother? Especially when it requires management attention to get it anywhere meaningful with so much else that is bigger and more important to deal with.
CPaaS vendors: Best of breed vs best of suiteI learned about the concepts of best of breed and best of suite when working at Amdocs.
- A best of breed vendor would specialize vertically, offering its customers a solution that is great in a narrow domain. Think of it as “the leading SMS vendor”. You do SMS and only SMS and you do it really well
- Best of suite is all about the breadth of your offering. You provide a solution that has a mixture of multiple services and features your customers will need. You might not be doing any of them the best in the market, but if someone needs multiple services and wants a single vendor to work with – you’re the best for them. Think of it as offering SMS, voice, email, video, … – Twilio
Twilio started with SMS and voice. It later decided to expand and become “best of suite” by attaching to it email, video, IOT, social messaging, chat , …
What happened though is that in parallel, it worked hard on being best of breed in voice and SMS. Doing that by going upstream and introducing Flex. Flex reduced the effort of contact centers built on top of Twilio.
And then they pivoted. With the acquisition of Segment and the need to tightly integrate it with their CPaaS and Flex offering. Transitioning from taking care of communications to taking care of understanding the customer.
Today?
There are two types of CPaaS vendors:
- The best of suite ones, who offer the breadth of communication services
- Or the best of breed ones, who focus on a specific domain. And the domain I care about is WebRTC and video. These usually won’t have legacy telephony. At most, they will enable connecting to legacy telephony of third parties
Interestingly, both are circling like vultures around Twilio to see which customers are going to come out of there looking for alternatives. Some of these CPaaS vultures offer pure WebRTC video solutions. Others offer the whole suite. And there are those who don’t even offer video – but see this as an opportunity to poach customers from Twilio.
The cases of Twilio IOT and Twilio LiveI remember that in one of the first Twilio Signal events, Jeff Lawson stood on stage and proudly announced that they never deprecated an official API. The way this was later handled is by having beta and GA phases for products.
This cannot be said anymore… by the end of 2022, Twilio started sunsetting and shutting down services.
It started with a round of layoffs at Twilio. Jeff Lawson, Twilio’s CEO, wrote a message that got to the Twilio blog as well. Here’s what we shared about it at the time with our WebRTC Insights clients:
- Twilio laid off 11% of their workforce
- The decision was to take the internal email and publicly put that on their blog, instead of getting it indirectly on TechCrunch
- A few interesting to note in this email:
- Twilio has 4 focus areas: reliability+trust, profitability of messaging, Segment adoption, Flex customer base
- 3 main products in focus: messaging, Segment (Customer Data Platform), Flex (Programmable Contact Center)
- Programmable Video isn’t prioritized at all. Programmable Voice might be said to be buried somewhere in there under Flex
- Twilio’s future success and growth lies Segment and Flex – not in Communication APIs
- The charts below show the number of employees and growth rate of Twilio in recent years
- Why is Twilio doing this? A few options here
- Growth is slowing, and all the hiring they did is just too much to maintain
- Management has too many directions it is now looking at, so it was time to shoot down all the smaller initiatives and products since they won’t bring the necessary growth at Twilio’s size
- Twilio might have used the current market state to clean the stables and remove all the useless fat from the company
- All of the above, to some extent
- How will this affect other CPaaS vendors? This is hard to say. Here are a few thoughts
- If Twilio is in poor shape, then the rest are in worst one
- With Twilio management shifting focus elsewhere, the API space, and especially in voice and video, it is down on these areas to build some differentiation
- Time to use FUD in the market against using Twilio for video APIs – Jeff just said it isn’t a focus area. Just make sure it doesn’t backfires…
- Maybe CPaaS isn’t as great as it was believed to be as a business…
- From my past life I know that selling to developers is super hard
- And the target market for it is rather limited
- There are better opportunities out there, which is why many CPaaS vendors are following in Twilio’s steps when it comes to Flex
- Also, if you are looking for developers, it might be worthwhile to try and poach a few of those who still work at Twilio, or more easily those who are looking for a new job
After the reduction in workforce, came the reduction in product offerings. The first two to go through the chopping block were Twilio IOT and Twilio Live.
Twilio Live was announced dead in November 2022. Low traction of the service and little fit the the direction of Twilio meant this had to die. The way this was done? Let customers know. Officially suggest they go use Mux instead. Somehow, the fact that Mux at the time had a service competing directly with Twilio Programmable Video wasn’t something that worried Twilio.
Twilio IOT was simply sold off to KORE Wireless in March 2023.
Remember that suggestion we gave about FUD in the market against using Twilio for video APIs? (I marked it in yellow above so you won’t miss it)
The demise of Twilio Programmable VideoHere’s what the Twilio product menu looks like on their homepage:
This is likely going to change soon or by the time this gets published.
- Customer Data = Segment offering
- Communications = CPaaS
- Applications = Enterprise stuff
Each and every piece in the Communications part can be snuggly fit into the products on the left and on the right (Customer Data and Applications).
Video is a bit of a stretch. At least if you look closely at traffic sizes and revenue numbers.
The two other oddballs – IOT and video streaming – were thrown out without too many objections and without hurting Twilio’ bottom line.
What was left was to get rid of the video piece. It likely took too many resources but made no real dent in Twilio’s numbers.
To be frank – the problems likely started with the acquisition of Kurento. Kurento wasn’t fit for what they had in mind for it, and it was riddled with architectural and technical issues. This wasn’t a good starting point for multiparty calling in Twilio Programmable Video.
If I had to guess, a lot of technical debt went into the product to improve and repurpose the media server pieces of Kurento.
Twilio was slow to innovate on video, leaving the room for other vendors – big and small. It missed the lowcode and embeddable experiences that are now common in video APIs. They didn’t invest in AI integrations too much. It didn’t optimize media quality enough to work well for its customers.
And then it left the door open for Amazon with their Chime SDK to threaten them in this domain.
I am guessing growth and revenue from Twilio Programmable Video wasn’t in line of expectations (unsurprisingly). The current market climate, the end of the pandemic, the headaches in Segment and Flex. All of it got them to the conclusion that it would be simpler to just sunset Twilio Programmable Video and move on.
A brave decision. Twilio Programmable Video couldn’t have been sunset in the worst time (unless you consider a few months prior to the pandemic and the quarantines).
A week before this announcement from Twilio, Amazon announced support for video calling in Amazon Connect.
Amazon is investing in adding video to its contact center solution, and Twilio, who has Twilio Flex competing against Amazon Connect, is sunsetting video support for its video API.
- What does it mean for video calling support in Twilio Flex?
- Would Twilio still support or add video calling to Twilio Flex without offering Programmable Video APIs?
- How should contact center customers view this? If they have video requirements in their roadmap, would they use Amazon Connect or Twilio Flex?
Why was Twilio Programmable Video appealing to potential customers? I can think of two main reasons:
- Single throat to choke. Sourcing your voice, SMS and video from the same vendor, on a single bill is an advantage
- A reputable vendor. It is Twilio. They are big. What can ever go wrong? …
The reasons why not to? Quite a few:
- Quality wasn’t on par with what can be achieved elsewhere with CPaaS vendors
- No lowcode/embeddable offering for its video API
- Support… could be better
- No innovation
All that Twilio had for itself is its brand name. And that in a market that was moving on.
Things other vendors have been doing in that period of time?
- Doubling down on large scale sessions, with 10,000 or more users
- Live streaming solutions (the one Twilio sunset in 2022 – Twilio Live)
- Investing in AI integrations and pipelines, both on client side and on server side
- 3D audio, VP9 video codec support
- Nocode/lowcode solutions
Twilio wasn’t able to keep up. Or even pick a direction it wanted to invest in.
The rise of the Zoom Video SDKTwilio issued an email to its customers on December 5, stating the sunset will take a full year. From this email:
[…] we have decided to End of Life (EOL) our Programmable Video product on December 5, 2024, and we are recommending our customers migrate to the Zoom Video SDK for your video needs.
The official recommendation from Twilio is for their customers to migrate to the Zoom Video SDK.
The announcement can’t be found (yet) on any marketing material from Twilio. It can be found on social media accounts from Zoom.
Why Zoom?
- Zoom isn’t a competitor of Twilio in anything, and are unlikely to be any time soon
- It is a large and respectable vendor with a brand name
They couldn’t suggest vendors that have SMS or voice services.
The rest are mostly smaller vendors – not something Twilio wanted to be identified with is my guess.
There’s only one problem with picking Zoom Video SDK here. Their web experience isn’t on par with the rest of the pack. They rely on WebTransport+WebCodecs+WebAssembly, which isn’t as stable or performant as just using WebRTC. For native, their SDKs should be fine, but for web browsers, I’d be reluctant to use them yet. Add to that the fact that this is a technology shift, requiring some relearning of terms and a reliance on proprietary technology, and you get some increased risk for the vendors switching.
I wonder if Twilio and Zoom came to an agreement here (with Zoom maybe even paying for this suggestion to go out) or if Twilio simply decided to offer some kind of a recommendation and be done with it. Philipp’s bet: Eric had dinner with Jeff and paid for it.
Anyhow, customers have a full year to figure out a solution. Or less – depending on how much browsers WebRTC implementations drift away from the current implementation of Twilio. What doesn’t get maintained in WebRTC rots rather quickly.
The future of managed Video APIs (without Twilio)I am not sure how much Twilio Programmable Video would be missed.
Developers certainly used it. Big and small. Its revenue was probably higher than some of the smaller video API vendors out there. These developers will figure out a way to migrate to other vendors to use. It won’t be the first time a CPaaS vendor has existed in the video API market (we had AddLive, vLine, ooVoo, SightCall, Respoke, Tropo, Forge, CafeX, Circuit, Bit6 all exit this market in the past).
3-4 years ago, we had 3 top dogs in this market: Vonage, Twilio, Agora
A year ago, I’d say I heard a lot more about Vonage, Amazon Chime SDK and Twilio. Less so Agora
Now, we have Vonage and Amazon Chime SDK
Who will take the 3rd spot in the 3 runners when it comes to developers’ mindshare in this industry?
We have Agora, Daily, Dolby, LiveKit and others who are all vying for that spot. Each has its own angle and differentiation.
Would Vonage keep its spot there?
Will Amazon continue investing in its Chime SDK enough?
I don’t have the answers to these questions, but I do have my own opinions.
Where should Twilio Video customers go from here?That is the big question.
If you are using Twilio Programmable Video – who should you go to instead?
And if you are on the lookout for a CPaaS vendor now – who should you pick?
My WebRTC Developer Landscape infographic was last updated in 2022, but can still offer some guidance as to the alternatives available. Some of them I’ve listed throughout this article. Others are just as valid.
Here are a few questions you need to answer for yourself:
- What are your requirements and focus? Different CPaaS vendors offer a different type of a solution, so pick one that offers what it is you’re after
- Make sure you ask around. Check references. Talk with other developers who use that CPaaS vendor
- Try them out in a small POC before fully committing yourself
- Check their commitment and level of investment in what it is you focus on as your requirements and roadmap. Don’t only listen to what they say – also check out what features they introduced to the market in the last 12-24 months. See if they had layoffs in that same period of time as well
- Don’t invest in abstraction layers to be able to replace CPaaS vendors. It sounds like a great initiative and project, so just don’t do it. Unless you want to use more than a single vendor at a time (unlikely for most of us)
- While you shouldn’t invest in an abstraction layer, you should definitely try to limit calls to the CPaaS vendor’s APIs to specific modules in your code. If you can limit it to a single source file or class – even better
The post Twilio exits video APIs, further focusing on voice, SMS and Segment appeared first on BlogGeek.me.
Third time’s a charm: WebRTC Insights, 3 years in
Let’s look at what we’ve achieved with WebRTC Insights in the past three years and where we are headed with it.
Along with Philipp Hancke, I’ve been running multiple projects. WebRTC Insights is one of the main ones.
Three years ago, we decided to start a service – WebRTC Insights – where we send out an email every two weeks about everything and anything that WebRTC developers need to be aware of. This includes bug reports, upcoming features, Chrome experiments, security issues and market trends.
All of this with the intent of empowering you and letting you focus on what is really important – your application. We take care of giving you the information you need quicker and in a form that is already processed.
Three years into this initiative, this is still going strong. We’ve onboarded a new client recently, and this is what he had to share with us on the first week already:
“[The Insights] Newsletter has been great and very helpful. Wish we had subscribed 2 years ago.”
Sean MacIsaac, Founder and EVP, Engineering @ Roam
Why is the WebRTC Insights so useful for our clients?It boils down to two main things:
- Time
- Focus
We reduce the time it takes for engineers and product people to figure out issues they face and trends on the market. Instead of them searching the internet to sift through hints or trying to catch threads of information on things they care about, we give it straight to them – usually a few days before their clients (or management) complains about it.
On top of it, we increase their focus on what’s important to them. Going back to past issues to find problems, search issues, look at security problems, know of experiments Google is doing or just be aware of the areas where Google is investing their efforts – all of these become really simple to do.
In the past few weeks we’ve been getting complaints from clients about audio issues on Mac (usually acoustic echo problems in Chrome). These were already hinted to in one of our previous issues and the full details appeared in the more recent issues. In parallel, we’ve been able to sniff around for root causes for them almost in real-time – enabling them to zero in on the problem and find a suitable workaround.
If I weren’t so modest, I would say that for those who are serious about WebRTC, we are a force multiplier in their WebRTC expertise.
WebRTC Insights by the numbersSince this is the third year, you can also check out our past “year in review” posts:
This is what we’ve done in these 3 years:
26 Insights issued this year with 329 issues & bugs, 136 PSAs, 15 security vulnerabilities, 230 market insights all totaling 231 pages. That’s quite a few useful insights to digest and act upon.
We have covered over a thousand issues and written more than 650 pages.
WebRTC is still ever changing – both in the codebase and how it gets used by the market.
Activity on libWebRTC has cooled down yet again in the last year, dropping below 200 commits a month consistently:
This is more visible by looking at the last four years:
On one hand WebRTC is very mature now, on the other hand it seems to us that there is still a lot of work to be done and bugs to be fixed. External contributions were up. What is concerning is that the “big drop” in May happened three months after Google announced a round of layoffs but we have not seen many departures of long-time contributors.
Let’s dive into the categories, along with a few new initiatives we’ve taken this year as part of our WebRTC Insights service.
BugsThe number of reported external bugs has dropped considerably as did the number of issues tracking new work and initiatives. This correlates with the decreased commit activity.
The areas for bugs also shifted, we have seen a lot more issues related to hardware acceleration (since Google is eying that now to further reduce the CPU usage in Google Meet). Operating systems are starting to become a bigger issue, for example MacOS Sonoma caused quite a few audio issues and enabled overlaid emoji reactions (a bad choice with consequences described here) by default as part of a bigger push to move features like background blur to the OS layer. And of course, every autumn brings a new Safari on iOS release which means a ton of regressions…
A good example of how Philipp himself uses Insights as a way to identify what change caused a regression was the lack of H.264 fallback on Android which rolled out in Chrome 115 in August. We had been commenting on the original change end of May:
That said, we did not think of Android which remains complicated when it comes to H.264 support. Thankfully this rollout was guarded by a feature flag so the regression could be mitigated by the WebRTC team in less than two days.
PSAs & resources worth readingIn addition to the public service announcements done by Googlers (and Philipp) as part of making changes to the C++ API or network behavior we continue to be tracking Chromium-related “Intents” (which are a useful indicator for what is going to ship) and relevant W3C/IETF discussions in this section. We also moved more in-depth technical comments on relevant blog posts from the “Market” section which made the overall decline in activity less visible here.
Experiments in WebRTCChrome’s field trials for WebRTC are a good indicator of what large changes are rolling out which either carry some risk of subtle breaks or need A/B experimentation. Sometimes, those trials may explain behavior that only reproduces on some machines but not on others. We track the information from the chrome://version page over time which gives us a pretty good picture on what is going on:
We have gotten a bit better and now track rollout percentages. We have not seen regressions from these rollouts in the last year which is good news.
WebRTC security alertsThis year we continued keeping track of WebRTC related CVEs in Chrome (15 new ones in the past year). For each one, we determine whether they only affect Chromium or when they affect native WebRTC and need to be cherry-picked to your own fork of libwebrtc when you use it that way.
In recent months we’ve seen a trend of looking more closely at the codec implementations to find security threats there. Our expectation is that this will continue in the coming year as well – expect more CVEs around this area.
A personal highlight was Google’s Natalie Silvanovich following up on a silly SDP munging thing Philipp did with CVE-2023-4076 which affected WebRTC munging in Chrome (but not native applications:
If only anyone had told us that using SDP in the API, let alone having Javascript manipulate it in the input, is a bad idea…
WebRTC market guidanceWhat are the leaders in video conferencing doing? What is Google doing with Meet, which directly affects WebRTC’s implementation? Are they all headed in the same direction? Do they invest in different technologies and domains?
How about CPaaS vendors? How are they trying to differentiate from each other?
Other vendors who use WebRTC or delve into the communication space – where do they innovate?
Here’s a quick example we’ve noticed when Twilio worked on migrating their media servers to different IP and ports:
This ability to look at best practices of vendors, how they handled such challenges, or introduced new features is an eye opener. These are the things we cover in our market guidance. The intent here is to get you out of your echochamber that is your own company, and see the bigger world. We do that in small doses, so that it won’t defocus you. But we do it so you can take into account these trends and changes that are shaping our industry.
The interesting thing is that as WebRTC goes more and more into a kind of a “maintenance mode” with its browser releases, the variance and interesting newsworthy items we see on the market as a whole is growing. This is likely why our market insights section has seen rapid growth this year.
Insights automationWe’ve grown nicely in our client base, and up until recently, we sent the emails… manually.
It became a time consuming activity to say the least, and one that was also prone to errors. So we finally automated it.
The WebRTC Issue emails are now automated. They include the specific issue along with the latest collection security issues. It has made life considerably simpler on our end.
Join the WebRTC expertsWe are now headed into our fourth year of WebRTC Insights.
Our number of subscribers is growing. If you’ve got to this point, then the only question to ask is why aren’t you already subscribed to the WebRTC Insights if WebRTC interests you so much?
You can read more about the available plans for WebRTC Insights and if you have any questions – just contact Tsahi.
Oh – and you shouldn’t take only our word for how great WebRTC Insights – just see what Google’s own Serge Lachapelle has to say about it:
Still not sure? Want to sample an issue? Just reach out to me.
The post Third time’s a charm: WebRTC Insights, 3 years in appeared first on BlogGeek.me.
Qotom Q20321G9 fanless PC
As PCengines announced the end of sales of their famous APU platform, it’s time to look for alternative devices that can be utilized as firewalls or network probes or VPN appliances.
I bought recently a Qotom Q20321G9 mini-PC from AliExpress. The model is similar to their Q20331G9 model described on Qotom website. The difference is a slower CPU and less SFP+ interfaces:
ModelQ20321G9Q20331G9CPUIntel Atom C3558RIntel Atom C3758RTDP17W26WNICs2x SFP+, 2x SFP, 5x 2.5Gbit LAN4x SFP+, 5x 2.5Gbit LANComparing to the APU platform, this Qotom box is huge: 62mm high, compared to 30mm of APU enclosure, 217mm bright, and much heavier because of the massive heatsink. But it has much more to offer.
Two M.2 NVME sockets allow a redundant storage setup out of the box. Also, it supports ECC RAM (although the model I received had a non-ECC DIMM), so it can serve as a reliable hardware platform if you need a long-term service. Also, it has an M.2 socket for an LTE modem, two antenna mounting holes, and a nano-SIM card slot.
A minor downside is that even at idling, with all CPU cores running at 800MHz, the device is getting quite warm. The onboard sensors show the CPU core temperatures at around +42C to +44C, and the enclosure is rather hot at the touch.
I also have run a CPU stress test with the enclosure covered by a towel for about a half an hour, and the CPU temperature exceeded 60C, still functioning well.
A minor inconvenience is that the power button is too easy to press if you’re moving around it while testing. But the button is easy to remove, so that the power switch can be pressed by a pen when needed.
The SFP and SFP+ interfaces were recognized by Debian 12 out of the box.
The device arrived with a preinstalled Windows 10. The BIOS allows redirecting the console to the COM port, which is provided as an RJ-45 socket, with the same pinout as Cisco routers.
The NIC numbering is a bit non-intuitive, and the marking on the enclosure does not help much. Here are the interfaces as they’re seen by Debian, if you look at the device’s interface panel:
eno1 (SFP+)eno3 (SFP)enp7s0 (LAN)enp6s0 (LAN)enp8s0 (LAN)eno2 (SFP+)eno4 (SFP)enp5s0 (LAN)enp4s0 (LAN)Some diagnostics output below:
root@qotom01:~# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Address sizes: 39 bits physical, 48 bits virtual Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-3 Vendor ID: GenuineIntel BIOS Vendor ID: Intel(R) Corporation Model name: Intel(R) Atom(TM) CPU C3558R @ 2.40GHz BIOS Model name: Intel(R) Atom(TM) CPU C3558R @ 2.40GHz CPU @ 2.4GHz BIOS CPU family: 178 CPU family: 6 Model: 95 Thread(s) per core: 1 Core(s) per socket: 4 Socket(s): 1 Stepping: 1 CPU(s) scaling MHz: 52% CPU max MHz: 2400.0000 CPU min MHz: 800.0000 BogoMIPS: 4800.00 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology no nstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg cx16 x tpr pdcm sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave rdrand lahf_lm 3dnowprefetch cpuid_ fault epb cat_l2 ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust smep erms mpx rdt_a rdseed smap clflushopt intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves dtherm arat pln pts m d_clear arch_capabilities Virtualization features: Virtualization: VT-x Caches (sum of all): L1d: 96 KiB (4 instances) L1i: 128 KiB (4 instances) L2: 8 MiB (4 instances) NUMA: NUMA node(s): 1 NUMA node0 CPU(s): 0-3 Vulnerabilities: Gather data sampling: Not affected Itlb multihit: Not affected L1tf: Not affected Mds: Not affected Meltdown: Not affected Mmio stale data: Not affected Retbleed: Not affected Spec rstack overflow: Not affected Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected Srbds: Not affected Tsx async abort: Not affected root@qotom01:~# lsusb Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 003: ID 05e3:0608 Genesys Logic, Inc. Hub Bus 001 Device 002: ID 046d:c31c Logitech, Inc. Keyboard K120 Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub root@qotom01:~# lspci 00:00.0 Host bridge: Intel Corporation Atom Processor C3000 Series System Agent (rev 11) 00:04.0 Host bridge: Intel Corporation Atom Processor C3000 Series Error Registers (rev 11) 00:05.0 Generic system peripheral [0807]: Intel Corporation Atom Processor C3000 Series Root Complex Event Collector (rev 11) 00:06.0 PCI bridge: Intel Corporation Atom Processor C3000 Series Integrated QAT Root Port (rev 11) 00:09.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #0 (rev 11) 00:0a.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #1 (rev 11) 00:0b.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #2 (rev 11) 00:0c.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #3 (rev 11) 00:0e.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #4 (rev 11) 00:0f.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #5 (rev 11) 00:10.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #6 (rev 11) 00:11.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #7 (rev 11) 00:12.0 System peripheral: Intel Corporation Atom Processor C3000 Series SMBus Contoller - Host (rev 11) 00:13.0 SATA controller: Intel Corporation Atom Processor C3000 Series SATA Controller 0 (rev 11) 00:14.0 SATA controller: Intel Corporation Atom Processor C3000 Series SATA Controller 1 (rev 11) 00:15.0 USB controller: Intel Corporation Atom Processor C3000 Series USB 3.0 xHCI Controller (rev 11) 00:16.0 PCI bridge: Intel Corporation Atom Processor C3000 Series Integrated LAN Root Port #0 (rev 11) 00:17.0 PCI bridge: Intel Corporation Atom Processor C3000 Series Integrated LAN Root Port #1 (rev 11) 00:18.0 Communication controller: Intel Corporation Atom Processor C3000 Series ME HECI 1 (rev 11) 00:1a.0 Serial controller: Intel Corporation Atom Processor C3000 Series HSUART Controller (rev 11) 00:1f.0 ISA bridge: Intel Corporation Atom Processor C3000 Series LPC or eSPI (rev 11) 00:1f.2 Memory controller: Intel Corporation Atom Processor C3000 Series Power Management Controller (rev 11) 00:1f.4 SMBus: Intel Corporation Atom Processor C3000 Series SMBus controller (rev 11) 00:1f.5 Serial bus controller: Intel Corporation Atom Processor C3000 Series SPI Controller (rev 11) 01:00.0 Co-processor: Intel Corporation Atom Processor C3000 Series QuickAssist Technology (rev 11) 02:00.0 Non-Volatile memory controller: Phison Electronics Corporation PS5013 E13 NVMe Controller (rev 01) 04:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 05:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 06:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 07:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 08:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 09:00.0 PCI bridge: ASPEED Technology, Inc. AST1150 PCI-to-PCI Bridge (rev 03) 0a:00.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 30) 0b:00.0 Ethernet controller: Intel Corporation Ethernet Connection X553 10 GbE SFP+ (rev 11) 0b:00.1 Ethernet controller: Intel Corporation Ethernet Connection X553 10 GbE SFP+ (rev 11) 0c:00.0 Ethernet controller: Intel Corporation Ethernet Connection X553 Backplane (rev 11) 0c:00.1 Ethernet controller: Intel Corporation Ethernet Connection X553 Backplane (rev 11) root@qotom01:~# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Address sizes: 39 bits physical, 48 bits virtual Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-3 Vendor ID: GenuineIntel BIOS Vendor ID: Intel(R) Corporation Model name: Intel(R) Atom(TM) CPU C3558R @ 2.40GHz BIOS Model name: Intel(R) Atom(TM) CPU C3558R @ 2.40GHz CPU @ 2.4GHz BIOS CPU family: 178 CPU family: 6 Model: 95 Thread(s) per core: 1 Core(s) per socket: 4 Socket(s): 1 Stepping: 1 CPU(s) scaling MHz: 52% CPU max MHz: 2400.0000 CPU min MHz: 800.0000 BogoMIPS: 4800.00 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology no nstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg cx16 x tpr pdcm sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave rdrand lahf_lm 3dnowprefetch cpuid_ fault epb cat_l2 ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust smep erms mpx rdt_a rdseed smap clflushopt intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves dtherm arat pln pts m d_clear arch_capabilities Virtualization features: Virtualization: VT-x Caches (sum of all): L1d: 96 KiB (4 instances) L1i: 128 KiB (4 instances) L2: 8 MiB (4 instances) NUMA: NUMA node(s): 1 NUMA node0 CPU(s): 0-3 Vulnerabilities: Gather data sampling: Not affected Itlb multihit: Not affected L1tf: Not affected Mds: Not affected Meltdown: Not affected Mmio stale data: Not affected Retbleed: Not affected Spec rstack overflow: Not affected Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected Srbds: Not affected Tsx async abort: Not affected root@qotom01:~# lsusb Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 003: ID 05e3:0608 Genesys Logic, Inc. Hub Bus 001 Device 002: ID 046d:c31c Logitech, Inc. Keyboard K120 Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub root@qotom01:~# lspci 00:00.0 Host bridge: Intel Corporation Atom Processor C3000 Series System Agent (rev 11) 00:04.0 Host bridge: Intel Corporation Atom Processor C3000 Series Error Registers (rev 11) 00:05.0 Generic system peripheral [0807]: Intel Corporation Atom Processor C3000 Series Root Complex Event Collector (rev 11) 00:06.0 PCI bridge: Intel Corporation Atom Processor C3000 Series Integrated QAT Root Port (rev 11) 00:09.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #0 (rev 11) 00:0a.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #1 (rev 11) 00:0b.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #2 (rev 11) 00:0c.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #3 (rev 11) 00:0e.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #4 (rev 11) 00:0f.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #5 (rev 11) 00:10.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #6 (rev 11) 00:11.0 PCI bridge: Intel Corporation Atom Processor C3000 Series PCI Express Root Port #7 (rev 11) 00:12.0 System peripheral: Intel Corporation Atom Processor C3000 Series SMBus Contoller - Host (rev 11) 00:13.0 SATA controller: Intel Corporation Atom Processor C3000 Series SATA Controller 0 (rev 11) 00:14.0 SATA controller: Intel Corporation Atom Processor C3000 Series SATA Controller 1 (rev 11) 00:15.0 USB controller: Intel Corporation Atom Processor C3000 Series USB 3.0 xHCI Controller (rev 11) 00:16.0 PCI bridge: Intel Corporation Atom Processor C3000 Series Integrated LAN Root Port #0 (rev 11) 00:17.0 PCI bridge: Intel Corporation Atom Processor C3000 Series Integrated LAN Root Port #1 (rev 11) 00:18.0 Communication controller: Intel Corporation Atom Processor C3000 Series ME HECI 1 (rev 11) 00:1a.0 Serial controller: Intel Corporation Atom Processor C3000 Series HSUART Controller (rev 11) 00:1f.0 ISA bridge: Intel Corporation Atom Processor C3000 Series LPC or eSPI (rev 11) 00:1f.2 Memory controller: Intel Corporation Atom Processor C3000 Series Power Management Controller (rev 11) 00:1f.4 SMBus: Intel Corporation Atom Processor C3000 Series SMBus controller (rev 11) 00:1f.5 Serial bus controller: Intel Corporation Atom Processor C3000 Series SPI Controller (rev 11) 01:00.0 Co-processor: Intel Corporation Atom Processor C3000 Series QuickAssist Technology (rev 11) 02:00.0 Non-Volatile memory controller: Phison Electronics Corporation PS5013 E13 NVMe Controller (rev 01) 04:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 05:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 06:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 07:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 08:00.0 Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) 09:00.0 PCI bridge: ASPEED Technology, Inc. AST1150 PCI-to-PCI Bridge (rev 03) 0a:00.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 30) 0b:00.0 Ethernet controller: Intel Corporation Ethernet Connection X553 10 GbE SFP+ (rev 11) 0b:00.1 Ethernet controller: Intel Corporation Ethernet Connection X553 10 GbE SFP+ (rev 11) 0c:00.0 Ethernet controller: Intel Corporation Ethernet Connection X553 Backplane (rev 11) 0c:00.1 Ethernet controller: Intel Corporation Ethernet Connection X553 Backplane (rev 11) root@qotom01:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: enp4s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:76 brd ff:ff:ff:ff:ff:ff 3: enp5s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:77 brd ff:ff:ff:ff:ff:ff 4: enp6s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:78 brd ff:ff:ff:ff:ff:ff 5: enp7s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:79 brd ff:ff:ff:ff:ff:ff 6: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:7a brd ff:ff:ff:ff:ff:ff 7: eno1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:7b brd ff:ff:ff:ff:ff:ff altname enp11s0f0 8: eno2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:7c brd ff:ff:ff:ff:ff:ff altname enp11s0f1 9: eno3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:7d brd ff:ff:ff:ff:ff:ff altname enp12s0f0 10: eno4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN mode DEFAULT group default qlen 1000 link/ether 20:7c:14:f2:9c:7e brd ff:ff:ff:ff:ff:ff altname enp12s0f1Zooming in on remote education and WebRTC
An overview of remote education and WebRTC. The market niches, challenges and solutions.
Whenever a video meetings company starts looking at verticals for the purpose of targeted marketing, one of the verticals that is always there is education. We’ve seen this during the pandemic – as the world went into quarantine mode, schools started figuring out how to teach kids remotely.
The remote education market is not just schools doing remote video calls. It is a lot more varied. I’d like to explore that market in this article.
Table of contents- How big can remote education really get?
- Me? Remote education?
- The role of WebRTC in remote education
- Top down decisions; sometimes
- Live, online and in-person
- Hybrid
- Moderation
- Assessment
- Collaboration and whiteboarding
- The challenge of engagement
- The challenge of engagement (part 2)
- Asymmetry in remote education
- Training the educators
- A matter of costs
There are around 2 billion children in the world. Over 80% of them attend schools.
Some 235 million higher education students are out there as well around the globe.
During the pandemic, a lot of them were online, taking classes remotely. For multiple hours each day.
The slide above is from Kranky Geek 2020. In this session, Google talked about their work on WebRTC in Chrome.
Here they shared the increase in video minutes during the initial quarantines. The huge spike there starts at around the August/September timeframe, when schools start.
Remote education is here to stay. Not with its increased usage of 10-100x, but definitely bigger than in the past. There are many places where remote education can fit – and not only for emergencies such as the pandemic.
Me? Remote education?Like everyone else, my kids went through the process of remote education during the pandemic. Here, the Ministry of Education went all-in with Zoom for schools (along with Google Classroom and Microsoft Office – go figure). Since then, our kids have on and off private tutors doing classes remotely sometimes. And now, when we have a war raging between Gaza and Israel, depending on where you live, you might be studying from home or physically in school.
I had my share of consulting with education organizations across the globe. Some focusing on schools, others with universities and some with private tutoring. It was always fascinating to see how such markets are distinctly different from each other, and how remote education also takes different shapes and sizes based on the country.
And then there are my own online courses, with their associated office hours and AMAs.
The role of WebRTC in remote educationWebRTC plays an important role in the education market. Besides offering video communications, it also enables the ability to mesh the communication experience directly into the LMS (Learning Management System) or the SIS (School Information System), offering a seamless and tailored experience for both the teacher and the learners – one that enables the educators to implement various pedagogies.
Remember here that WebRTC is a synchronous technology – live, real-time voice and video communications. A large chunk of the education market is leaning heavily on asynchronous learning (recorded videos, texts to read, etc). These are not covered in this article.
Here are some market niches and use cases where you will find WebRTC in remote education.
Group lessonsThe simplest one to explain is probably group lessons. The classic one would be the pandemic use case, where during quarantine, schools went all virtual – classes were conducted online.
Remote group lessons aren’t limited to schools either – they are done in universities, private group tutoring, etc.
Main challenges here include:
Moderation tools for the teachers. Ones that are simple to use while conducting the lesson itself
Collaboration tools to make the lessons more engaging. Maintaining engagement in online group lessons is the biggest challenge at the moment, especially for younger learners
Authentication and authorization of users. Lots of anecdotal stories around this one throughout the pandemic
One thing that is raised time and again with group lessons, especially in schools, is the need (and inability) to get the students to keep their cameras on. This is a huge obstacle to effective learning, and something that needs to be taken into account.
Another important thing that needs to be fleshed out early on here, is who is the client – is it the teacher or the students. Whoever the system is geared towards will set the tone to how the solution gets designed and implemented.
One-to-one tutoringThese are mainly one on one lessons conducted remotely.
Outside of the domain of classic education, a lot of classes are actually conducted in such a way. Here are a few anecdotal stories from recent years that I’ve learned about:
A dear friend who is learning to play the piano. Remotely. She travels a lot between the US and Israel, and takes her lessons from everywhere through her iPad
Another friend, taking 1:1 drawing lessons
Online chess lessons for kids in our community
My son’s friend, learning C++ on Unreal engine, taking 1:1 lessons
My son, a few years ago, when he was 10 or so, learning to build online games using nocode game engines from an 18 year-old who lived two cities away
My wife took online dance lessons to specialize in Salsa from a renowned instructor abroad
Besides the collaborative, engagement level and nature of such lessons, it is important to note that they aren’t suitable for everyone. Some teachers are more natural in these, and some students can learn effectively in such a manner while others struggle (I have both examples at home).
An interesting use case here that I’ve seen is math and English (!) tutors from India and China teaching remote kids in the UK and the US. Why? Simply because they are cheaper than using local teachers. Then there was the opposite – rich Chinese families getting one-to-one English tutoring for their kids from US teachers. Go figure.
One-to-one tutoring comes in a lot of different shapes and sizes.
MOOCs (Massive Open Online Courses)MOOCs were all the rage 10 years ago. Their market is still consistently growing.
MOOCs are simply large online courses that are open for people around the globe. Some of them are collaborative, while others are mainly lecturer driven. Some allow for asynchronous learning while others are more synchronous in their nature. Both the asynchronous and synchronous learning modes in MOOCs offer self-paced learning (at least to some degree).
WebRTC finds its way into MOOCs for their synchronous part, when that requires live video sessions – either between lecturers and students or between student groups in the more collaborative courses.
ProctoringProctoring isn’t about learning, but about taking exams. Remote proctoring enables taking exams at the comfort of one’s home or office without going to the classroom.
With proctoring, the user is required to open up his camera and microphone as well as share his screen while taking the exam. The proctoring application takes care of checking that other tabs aren’t being opened and that nothing fishy is taking place (as much as possible). WebRTC is used to gather all that realtime audio and video data and record it. If needed, these recordings can be accessed by human proctors later on.
It should be noted that for proctoring, there are a lot of requirements around circumventing the ability to cheat on the exam. This includes things like monitoring applications used during the exam, maintaining focus on the exam page, etc. To achieve this, most proctoring solutions end up as PC applications (usually using Electron) which the student needs to install on his machine in order to take the exam. The innards of the proctoring application will end up using WebRTC in a web application – simply for its speed of development and the use of the WebRTC ecosystem.
CoachingWhile similar to classic education, coaching is slightly different. In its essence, these can be 1:1 sessions or small group sessions where issues and challenges in certain areas get fleshed out. In group lessons and 1:1 tutoring, a lot of the focus is on collaboration features. Here, in many cases, it will be more on the video of the participants and the need to bring them together.
Another interesting aspect of coaching is the platform it gets attached to – either directly or indirectly. Coaching often comes bundled as a larger course/training offering, mixed with in-person meetings, reading/presented materials and the coaching sessions themselves.
The LMS and SIS systems are usually also lacking in the coaching platforms. Usually, these will be geared towards flexible use and at times an integrated payment system.
WebinarsWebinars are a form of lessons that is conducted over the internet, mostly for businesses to assist in marketing and sales efforts. Depending on the level of interactiveness of the webinar, the need and use of WebRTC will be needed.
In the past, webinars were usually conducted via specialized downloadable applications, where the content was mostly slide decks and the voice of the speakers. The interaction with the audience was done via text messages and organized Q&A. Over time, these solutions became richer and more sophisticated, adding video communications as well as the ability of the audience to “join the podium” if and when needed.
Using WebRTC here enabled getting rid of the application download requirement and increased the level of interactivity quite considerably.
The intersection of education and healthcareEducation and healthcare are bound together. I’ve shown that a bit in my WebRTC in telehealth article, looking at it from the remote training of healthcare topics perspectives. I want to take a different angle on the same topic here. I’ll do that by showcasing two interesting use cases I’ve been privy to a few years back.
#1 – Dance lessons in cancer
I heard this one from a dancer who had cancer and healed. Women with cancer have it hard. Chemo is brutal – it seeps out the energy and causes hair loss. This means women don’t want to go outside that much. Here, being able to bring them remotely to a dance lesson can be a real benefit to them, especially if they love(d) dancing. They won’t go physically – not wanting to meet people outside and the stairs that come with it – along with the energy it takes. But they will be willing to dance – maybe.
Remote dance lessons for this niche is beneficial. Not from an educational standpoint but more from a mental health one.
#2 – Video in class for students in hospitals
Another vendor I worked with briefly was assisting school kids who had to be treated in hospital or just stay home for prolonged periods of time (think weeks or months at a time). Their solution was to bring a video conferencing system and rig it in the physical classroom of the kid as well as where he is located, be it home or a hospital bed.
This way, the kid could join the classes as well as stay connected to other classmates during recesses. The main purpose here isn’t really the teaching part, but rather to make sure the student stays in contact with peers in his age group and not be secluded during that period of time.
Is this a use case in education? In healthcare? I can’t really say…
ERT (Emergency Remote Teaching)The pandemic showed us that remote education is challenging but might be necessary. We were all quarantined for long periods of time, with school across the globe going remote.
Here in Israel, when clashes with Gaza or Hezbollah in Lebanon flare, schools shift to remote learning. It isn’t frictionless or smooth, but it is the solution we have to try and continue educating kids here.
The most crucial aspect of ERT is that teachers are forced to change their teaching setting with no preparation. In Israel, at least, the pandemic didn’t prepare teachers for the current war – it feels like the education system in Israel learned nothing from the pandemic wrt to remote teaching
Top down decisions; sometimesEducation is interesting. Especially the institutional ones of schools.
In some countries, decisions are made top down while in others, there’s more autonomy kept at the school level or the district level.
Here are a few things I learned asking the question on LinkedIn, about what tool was used during the pandemic for virtual classes across the globe:
- Israel. Where I live. Was mostly Zoom during the pandemic
- There was also a bit of Google Meet and some BigBlueButton, due to its integration with MASHOV (an SIS in Israel)
- The government struck a deal in education for Google Classroom country-wide
- There’s also Office available for free for all students
- And Zoom was the decision for virtual classes
- This year, it all changed to Google Meet, presumably due to security concerns, but more likely this was due to pricing (Zoom renewal cost money while you get Google Meet and Microsoft Teams for free with Google Classroom and Office respectively)
- Zoom hurried up with a statement that it is secure and now available for free for the education system in Israel
- As the saying goes – it’s all about the money
- Bulgaria used Jitsi Meet (through the Shkolo platform); later replaced by Microsoft Teams. Both with government provided accounts
- Colombia. Most public schools and the university system relied heavily on Microsoft Teams. Private schools and universities were about an even split between Zoom and Microsoft Teams
- Austria was mainly Microsoft Teams
- Russia – Zoom
- The United States was mostly Zoom. It wasn’t mandated, but just how things ended up in most places
- UK. A private school in London opted for Microsoft Teams. Public schools were left to figure out their own solution
- Argentina. Zoom, though I am not sure if everywhere and if the decision was top down or bottom up
- India. Primarily Microsoft Teams and occasionally Zoom. Mainly because Microsoft Teams had better and stronger channel partners in India, being able to offer better deals
- France. Started with Zoom and Jitsi Meet in schools. Now, the government has built a large scale BigBlueButton infrastructure for virtual classrooms
This is by no means complete or accurate, but it shows a few important aspects of education:
In some countries, decisions on the tools to use is taken top down, while in others, each district or school is left to autonomously make a decision
Like in many industries, but probably more so, appearances matter. Losing Israel for Zoom was bad publicity. They had to fix that quickly by renewing the service for free. BTW – the damage is already done, my kids are now using Google Meet at school and there likely isn’t a way back
Live, online and in-personEducation is mixed. It isn’t all virtual and isn’t all in person.
My own WebRTC Courses are online, but not live. The lessons are pre-recorded. I offer monthly AMA meetings as part of them which are online and live.
I took a CPO course last year. It included in person meetings (3 full days), weekly live sessions as well as pre-recorded information.
My kids are now learning some days remote and some days in-person in the school.
Some countries had recorded/broadcasted lessons alongside virtual live classes during the pandemic, creating from them a full set of learning materials that students can use moving forward.
The LMS (Learning Management System) used needs to take all these into account, enabling different learning strategies and different content types. Your own service needs to be able to figure out what works best.
HybridThe term Hybrid Learning refers to any form that incorporates online and offline learning. This is slightly different from how we define hybrid meetings.
- As an example in Israel at the moment, in the current “war setup”, students go physically to school a few days a week and the rest they learn asynchronously or synchronously from home.
- Another example of hybrid learning is when students work with laptops in the traditional classroom.
Allowing a student to join remotely to a class taking place in-person is a real challenge, but one that needs to be dealt with as well. This isn’t any different from hybrid meetings in enterprises in terms of the basic need. The difference is likely in size and complexity.
Most classes aren’t geared to this. From the placement of the cameras in the class, to the way the lessons are conducted and to the way teachers need to split their attention between in person to remote students.
In most places, going hybrid in education is an intentional decision that can be made only for select use cases and in a limited number and types of institutions.
ModerationWho is allowed to join a virtual lesson? Should the teacher approve each student joining? How do you know who is online? Who is actively listening? Should anyone be automatically allowed to speak up? Share their screen? Is there a way to check if the student goes “off the reservation”, doing other things in other browser tabs or on his phone in parallel?
All these are hard questions with no good answers.
Moderation in education must take place – especially for group lessons. This has two purposes:
- Maintain a semblance of order
- Let the teacher focus on teaching
Oftentimes, moderation tools deal with a semblance of order but less with the focus of the teacher or teaching.
The decision in Israel for example to go for Google Meet makes total sense simply because authentication and identity is managed by Google Classroom already. Classroom is acting as the LMS as well, or at least the hub for students and teachers. Having a tighter integration means some of the moderation requirements can more easily be met.
It isn’t only about what can be moderated, but how and with what level of friction
AssessmentHow are assessments taking place in online learning?
In the traditional classroom, teachers physically saw the students and could easily gauge their level of attentiveness. To that, home assignments and tests were added.
Once going online, technology can come to assist the teachers and students, adding a layer of information to the assessment process. Dashboards can be built to make this data accessible.
Where does WebRTC fit in here? The same way it does in online meetings, where we see today a growing focus on incorporating transcriptions, meeting summaries and action items automatically. Similar LLM/generative AI technologies can be used to glean insights out of online lessons.
In many ways, this isn’t done yet. Probably because we’re still struggling with engagement (see below).
Collaboration and whiteboardingHow is collaboration done in education? Do we need the classing blackboard/whiteboard for teaching? How does that get translated to the digital, remote scenario?
Are we looking here for something as powerful and flexible as a Miro board or something simpler and less feature rich?
Is teaching math or physics similar to teaching languages or literature when it comes to collaboration and whiteboard?
How about Kahoot or similar polling/quiz capabilities? Do we make them engaging or boring as hell?
A lot of thought and energy needs to be diverted towards these types of questions, in trying to figure out what works best to increase engagement and improve the learning experience (and by extension, the learning itself).
The challenge of engagementHow do you define engagement in online synchronous lessons?
Is students opening cameras considered engagement?
Maybe students be engaged with their cameras turned off
Getting students to open up their cameras, having them choose to do so and keep the cameras on is a big issue in schools and in higher education.
In my son’s school, they are now shifting towards enforcing students to open their cameras… but allowing them to point that camera at the ceiling
Once you have cameras on, how does a teacher gauge the level of engagement of a student? How does he spare the time looking at 20+ students (36 in Israel classes) to understand if they are engaged or not while trying to present his screen to teach something out of his slidedeck?
“Feeling the crowd” to understand if a topic needs further explanation or can the teacher move on to new topics is harder to achieve online than it is in person.
The challenge of engagement (part 2)How do you get students engaged?
What type of collaboration solution do you need?
Which experiences should be baked into the solution?
My son decided to take up Russian. His friend speaks Russian with his parents, so he decided he wants to understand when they talk to each other (go figure). He decided independently to install Duolingo on his phone and has been taking their lessons for almost a year now
He can now read Russian and know quite a few words.
A good friend of mine is learning German using Duolingo. We did a roadtrip in the US in February. I had to hear him learn in our long hours on the road. It was an interesting experience to see it from the side, trying to figure out how this magic happens.
Engagement and “gamification” are a main part of how Duolingo works and how it gets students back into their app over and over again.
We haven’t quite cracked the formula of how to do this well in live virtual classes. There must be a way to get there, and when we find it, we will see great dividends from it.
Asymmetry in remote educationThere are teachers and there are students. Who is the system designed to cater?
A simple question. Answering with “both” is likely going to be wrong most of the time.
I had a meeting at a large and prominent university in Europe a few years back. They wanted to build a video conferencing system for lectures. Have the professor in front of a large digital board showing tens of students joining remotely. Call it extremely expensive and unique. That was before the pandemic, so unrelated to it.
The question I had was who this system is for. Is it to sell students on a great remote experience or is it for the professor to feel important. I have my own answer here
You need to decide who the service you are developing is really there to cater – the teacher and his needs, assuming that students will simply join because they have little choice. Or the students, focusing on enticing them to join, collaborate and interact.
Doing both at the same time is a real challenge, and one that most vendors aren’t prepared to take yet.
Figure out who your main user is. The teacher or the students. Or maybe the parents?
Training the educatorsSomeone needs to teach the teachers how to use the service. This is a real problem, especially when going mainstream.
When the pandemic started and Zoom was selected here in Israel, a lot of videos surfaced explaining how to use Zoom in the context of teaching with it. Last month, when Google Meet was the official solution, you started seeing the same occur for Google Meet here in Israel.
The differences between these two services may seem minor, but they are big for teachers who aren’t technically savvy.
Some private tutors for example shy away from remote lessons. Their reason is the inability to focus on the student during the lesson. Increase that by 20-40 students in a single lesson, many of them acting like prisoners trying to break out and figuring out ways to game the system called a virtual lesson, and you get to the need for teachers who know their way using the service inside and out.
Onboarding and familiarizing teachers to the platform is just as important as the actual service, sometimes even more
A matter of costsThis one might just be an opinion of mine.
Remote education is a huge market. During the pandemic, it encompassed almost all the world’s students. And yet, the amount of money available to spend per minute is quite low.
In many cases, the deals are large (in front of a state or a country). Sometimes, they are smallish, in front of a single school. There’s money in these institutions, but in many cases, that money is spent elsewhere.
When going after the education market, it is vital to understand the buying habits and budget of the would-be purchaser beforehand.
Solutions in the education market need to be cost effective and efficient from a WebRTC infrastructure point of view
Where can I help, if at all?
Online WebRTC courses, to skill up engineers on this technology
Consulting, mostly around architecture decisions and technology stack selection
Testing and monitoring WebRTC systems, via my role as Senior Director at Cyara (and the co-founder of testRTC)
The post Zooming in on remote education and WebRTC appeared first on BlogGeek.me.
WebRTC in telehealth: More than just HIPAA compliance
When it comes to WebRTC in telehealth, there are quite a few use cases and a lot of things to consider besides HIPAA compliance.
A thing that comes up in each and every discussion related to telehealth & WebRTC is the value of the call in telehealth. We’ve seen video meetings and calls go down to zero in their cost/value for the user. Especially during the pandemic. So whenever we find a nice market where there is high value for a call, it is heartening. Healthcare is such a place where we can easily explain why calls are important.
But what exactly does WebRTC in telehealth mean? It isn’t just a patient calling a doctor. There is a lot more to it than that. Let’s dive in together to see what we can find.
Table of contents- My own experience with Telehealth
- Finding WebRTC in Telehealth
- A game of numbers
- WebRTC telehealth and HIPAA compliance
- Network and firewall restrictions
- Quality of media
- Asymmetric nature of users and devices
- Medical devices, sensors and telemetry
- SaaS, CPaaS & open source: Build vs Buy
Like many others, my first real bump with telehealth took place during the COVID quarantines.
My son was sick with high fever for over a week, and the doctors didn’t help any.
My wife was worried, needing more comfort by knowing someone was looking at him. Really looking at him.
So we used a kind of a private service that a hospital near our vicinity was giving:
- You subscribe and pay a hefty price
- They send over a kit
- You install an app and take measurements multiple times a day (useless ones, but stay with me)
- They send over a radiologist to do an X-ray scan (need something to show they can)
- Then you get to talk to a doctor once a day. Over a video call. From the same app
What can I say? It worked as advertised.
As a consultant and a product managerWe have quite a few healthcare clients using our various WebRTC services at testRTC.
Other than that:
- Took part of an RFP of the ministry of health in Israel by assisting the vendor who approached me win the contract
- I assisted vendors during the pandemic to troubleshoot their architecture and scale their service rapidly
That and just from conversations with vendors, along with a review of this article by a few who work on telehealth products and integrating their comments as well.
Does that make me an expert in telehealth? No.
But I can fill in the WebRTC angle of telehealth, which is a rather big one.
Finding WebRTC in TelehealthTelehealth for me is about the digital transformation of healthcare services.
It can start small, with things such as scheduling and viewing lab test results. And then it can grow towards virtualizing the actual patient-doctor interaction. Or any other interaction within the healthcare space between one or more people (emphasis on one here – not two).
I’ve listed here the main use cases that came to mind thinking of it in recent days.
Patients and doctorsThe most obvious use case is the patient and doctor scenario.
In this, the doctor visitation itself is remote and virtual.
This can be useful in many situations:
- When the patient can’t get to the doctor’s office
- During the pandemic:
- When healthcare providers didn’t want patients physically in the office
- If doctors are sick, but their numbers are dwindling due to them being quarantined, while they can still be useful as doctors remotely
- If you don’t want to waste a patient’s time in coming over and waiting
- When it is truly urgent (an emergency)
For many of these situations, this is the setup that takes place:
- Doctor – sitting in front of a PC or laptop. In a designated office or hospital (=managed network), or at home (=unmanaged network)
- Patient – connecting from a smartphone or tablet, via a direct link or an installed application
More on that – later.
In general – here’s where you’ll see such solution types deployed:
Hospitals and large healthcare organizations
Clinics hosting multiple doctors
Private clinic of a single doctor
Insurance companies
Also remember that the word doctor is a broad definition of the caretakers involved. These can be nurses, doctors, dietitians and other practitioners offering the treatment/session to the patient remotely.
The other thing to remember is that this is also asymmetric in scarcity: there are a lot more patients than they are caregivers.
Group therapy and counselingThen there’s group therapy.
One where one or more psychologists lead a larger group of patients. The same also applies to dietitians, speech therapists, smokers, cancer patients and other groups of practitioners.
Here again, the idea and intent is that the patients and the therapists can join remotely to a virtual meeting and conduct that meeting.
The main benefit? Not needing to drive and travel for the meeting and being able to conduct it from anywhere.
Notable here is the fact that this can be enhanced or taken to a slightly different perspective – this can encompass the allied health domain, where AA (Alcoholic Anonymous) groups for example fit in.
Nurse stationsThe nurse station is slightly different from the doctor-patient in my mind.
Here, the patient is situated physically next to the nurse, so the call/meeting isn’t virtual or remote but rather in person. The “twist” is that there is another caregiver or external authority that can be joined remotely to the session if and when needed. Say a doctor with a specialization that might not be available where the patient is located – this can be viewed in a way to democratize the access to specialty care.
Envision a nurse moving inside a hospital ward. She has a mobile station moving around with her that can be used to conduct video meetings with doctors. It can also be used for other purposes such as adding a live translator into that interaction with the patient or the patient’s custodian.
The lack of specialized provider access in remote areas can be extremely critical, and here again, virtual meetings can assist. Taking this further, a nurse station of sorts can be placed inside an ambulance providing immediate care – even for cases of strokes or cardiac arrests.
OutpatientsOutpatients are clinics that belong to hospitals. These are designed for people who do not require a hospital bed or an overnight stay. Sometimes, this can be for minor surgeries. Mostly for diagnostics, treatments or as follow ups to hospital admissions.
These clinics are part of the overall treatment that patients get from the hospital or for things that are hard to obtain elsewhere due to scarcity of machinery and/or experience.
Some of the diagnostics done in an outpatient clinic can be done remotely. This reduces wait times and travel times for patients and also allows using doctors joining remotely and not physically inside the clinic.
While similar to the patients and doctors use case, there are differences. The main one being the organization behind it, the logistics and the network. Hospital networks are usually a lot more complex and limited to connectivity of WebRTC traffic, bringing with it a different set of headaches.
Taking care of the elderlyAs the human population is aging in general and people live longer, we’re also getting to a point where elderly care is different from other areas of healthcare. Another aspect of it is the breakdown of the family unit into smaller pieces where elderly people move to assisted living, nursing homes and hospices.
Here, the telehealth solutions seen include also things like:
- The ability to easily communicate with family members and friends remotely to keep connected
- Remotely monitor and take care of the old via solutions that remind us of a surveillance use case
- Providing access to doctors remotely, especially for the less common health issues
Remote patient monitoring is another new field. Due to the scarcity of nurses, many hospitals are moving towards virtual patient monitoring for patients who are in hospitals or medical facilities that require 24×7 monitoring for critical patients.
Operating roomsThe operating room is at the heart of hospital care. It is where surgeons, anesthetics, nurses and other practitioners work together on a patient in an aseptic environment.
An obvious requirement here might be to have an expert join remotely to observe, instruct or consult during surgery. That expert can be someone who isn’t at the vicinity of the hospital, enabling to bridge the gap of knowledge and expertise existing between central hospitals in large cities to rural ones.
It can also be used to have an expert who is situated in the hospital join in – entering an operating room requires the caregiver to scrub before entering. This process takes several minutes. By having the expert join remotely from another room at the hospital, we can have him jump from one surgery to another faster. Think of the supervisor of multiple surgery rooms at a hospital or a specialist. Saving scrubbing times can increase efficiency.
Then there is the option of getting external observers into the surgery rooms without having them in the surgery room itself. They can be silent or vocal participants. Joining in as trainees for example, as part of their learning process to become surgeons.
As we advance in this area, we see AR and VR technologies enter the space, either to assist the doctor locally in the surgery or have the external experts join remotely.
TrainingLearning in operating rooms is just part of training in the healthcare domain.
Training can take different shapes and sizes here, and in a way, it is also part of the education market.
Here are some of the examples I’ve seen:
- Remote training/education for various healthcare roles
- First aid training for civilians
- Medical equipment training
Healthcare is a domain that has lots and lots and lots of devices and machinery. From simple thermometers to CT scanners and surgical robots.
What we are seeing in many areas is the remoting of these devices and machines. Having the patient being diagnosed or treated use a device (or have a device used on him), while having the technician, specialist, nurse or doctor operate or access the data of the device remotely.
This has many different reasons – from letting patients stay at home, to getting specialists from remote areas, to increasing the efficiency of the caregivers (reducing their travel time between visitations).
Here are a few examples:
Stethoscopes, Thermometers, Ophthalmoscopes, Otoscopes, etc. These devices can be made smart – having the patient use them on his own and have their measurements sent to remote nurses or doctors
X-ray, CT, MRI – different type of scans that can be done in one place and have the operator or the person deciphering the results located elsewhere
Surgical robots, that can be observed or operated remotely
Robots roaming hospitals, taking care of menial tasks such as sanitizing equipment and rooms
There is an ongoing increase in adding smarts into devices and the healthcare space is part of that trend. When caregivers need to interact with these devices or access their measurements in real time, this can be done using WebRTC technology.
Simultaneous translation and/or scribesDoctors are a scarce resource. As such, a critical part is having their time better utilized.
There are two telehealth solutions that are aiming to get that done in a similar fashion but totally different focus:
Translation – patients speaking a different language than that of a caregiver need a better way to communicate. Hospitals and clinics cannot always have a translator in hand available. In such cases, having a translator join remotely can be a good solution.
The purpose? Increase accessibility of doctors to patients who don’t speak the doctor’s language.
Scribes – doctors need to keep everything documented. The patient digital record (PDR) is an important part of treatment over time. The writing part takes time and is done in parallel to diagnosing the patient. It is quite common today to have a doctor sit in front of you, typing away on his PC without even looking at the patient (being on the receiving end of that treatment more than once, it does sometimes feel somewhat surreal). Remote scribes can alleviate that by taking part in the doctor visitation, taking care of filling in the PDR. A different approach making headway here is AI-based transcription and the automatic creation of the medical record entries – this alleviates the need for a human scribe.
The purpose? Increase efficiencies and enable doctors to treat more patients.
At the boundary between education and healthcareThen there is the education part adjacent to healthcare. Think of children who are treated for long periods of time where they either need to stay in the hospital or at home for treatment and rest. How do you make sure they don’t lose too much of the curriculum during that time? That they stay connected with their friends in class?
There are solutions for that, in the form of providing a PC at school and a tablet or laptop to the kid to remotely join such sessions.
This is probably more suitable for the education market, but I just wanted to add it here for completeness.
A game of numbersTelehealth is a relatively small WebRTC market.
If you take all physicians in the world, and try to figure out how many there are per the size of the population, you will get averages of 1:500 at most (see Wikipedia as a source for example).
Not all physicians practice telehealth. Of those who do, many do it seldomly. The size of the number here isn’t big when it comes to minutes or visitations conducted.
Compared to the number of minutes conducted every day on Facebook Messenger, the total telehealth minutes worldwide will be miniscule.
The difference here though, is the importance and willingness to pay for each such minute.
When trying to do market sizing or value – be sure to remember this –
Total number of doctors, minutes and visits isn’t that large worldwide
Telehealth minutes are more valuable than social media minutes
WebRTC telehealth and HIPAA complianceWhenever telehealth is discussed, HIPAA compliance is thrown out in the air. At its heart, HIPAA compliance is about security and privacy of patients and their information, all wrapped up in a nice certification package:
- Vendors wanting to sell telehealth services to hospitals need to be HIPAA compliant – at least in the US
- In the EU, there’s GDPR, with different interpretation per EU country
- Then there are other countries outside of the US and the EU with their own regulations
- All in all, the requirements here are quite similar
Most countries have separate regulations for patient privacy which are generally more stricter than personal privacy. While there’s more to it than what I’ll share here, it usually boils down to encryption and all the management that goes around it.
WebRTC is encrypted, so all that is left is for the application to not ruin it… which isn’t always simple.
Sometimes, you will find vendors touting E2EE (End-to-End encryption), which in most WebRTC jargon means the use of media servers who can’t access the media. Oftentimes, these vendors actually mean the use of P2P (Peer-to-Peer), where no media server is used at all.
Oh, and if you are using a third party video conferencing solution (say… a CPaaS vendor), then you will need to obtain a BAA (Business Associate Agreement) from that vendor, indicating that he complies with HIPAA. You will then need to certify your own application on top of it.
Network and firewall restrictionsHospitals and clinics usually end up with very restrictive internet networks. This stems from the need to maintain patient confidentiality and privacy. The increase in ransomware attacks on businesses and healthcare organizations is a source of worry as well.
To such a climate, adding WebRTC telehealth solutions requires opening more IP addresses and ports on the organizations’ firewalls.
A big challenge for vendors is to get their WebRTC applications to work in certain healthcare organizations. Usually because their services get blocked or throttled by deep packet inspection.
Vendors who can make this process smoother and simpler for customers will win the day.
Quality of mediaNot being able to see video well in a social interaction is acceptable.
Having a doctor not being able to see the mole on your skin is a totally different thing.
Quality of media can be critical in certain use cases of telehealth. Here, it might be a matter of resolution and sharpness of the image, but it can also be related to the latency of the session. Remote procedures conducted via WebRTC for telehealth might be a bit more sensitive to latency than your common meeting scenario.
Depending upon the use case, you have to prioritize resolution vs frame rate. A still patient needs higher resolution and surgery or any motion specific activity requires a higher framerate. The ability to switch between these two priorities is also a consideration.
At times, 4K requirements or specific color spaces and audio restrictions may be needed. Especially when dealing with analysis of sensor data from medical devices. These may require a bit more work to integrate properly with WebRTC.
Asymmetric nature of users and devicesOne tidbit about telehealth is that sessions are almost always asymmetric in nature and for the majority, they are going to end up as a 2-way conversation.
By asymmetric I mean that the users have different devices:
- Doctors and caregivers will almost always be on devices that are known in advance – their location, their makeup, etc.
- More likely, they will be accessing them from a laptop or a PC
- They use the same application again and again. This means that they will learn to workaround issues they bump into
- Often on a restricted device with older browser versions and/or low CPU power. Though not always and not everywhere
- Sometimes, though less and less these days, old equipment used by doctors in their office means the introduction of interop requirements
- Patients will almost always join from a mobile device – a tablet or a smartphone
- Many will do so via a URL they receive over SMS, joining from a mobile browsers
- Browser use on mobile isn’t as stable, especially on iOS Safari. Device handling is trickier with the need to handle phone calls and assistants (Siri) interacting with the same microphone
- Others will end up on a native application built for this specific purpose
- Being unassuming consumers, they try to join from everywhere. Including elevators or moving cars
- They are also not going to use the application much and won’t want to waste time mucking around figuring out things or troubleshooting them. This means telehealth apps need to relentlessly focus on UX and usability for the patient side
This asymmetric nature affects how telehealth applications need to be designed and built, taking special care around permissions, privacy and the unique user experience of the various users.
Medical devices, sensors and telemetryModern healthcare has the most variety of devices and sensors out there from all industries (leaving out the defense industry). These devices are now being digitized and modernized. Part of this modernization is adding communication channels for them, and even more recently – being able to virtualize and remote their use – either partially or fully.
Medical devices sometimes generate images. Other times an audio stream. Or a video feed. Or other sensory data and information. WebRTC enables sending such data in real time, or the telehealth application can send this data out of band, via Websockets or HTTP messages.
It can be as simple as taking a measurement of a patient remotely, while he is holding the medical device and the nurse or doctor observes him and the results sent over inside the application.
That can progress passively overseeing a procedure and commenting on it in a video session. Think of a doctor or a nurse consulting remotely with a specialist while giving a treatment or operating a surgical procedure.
And it can go to the extreme of remotely giving the procedure. A radiologist operating the CT machine remotely for example.
How these get connected and where WebRTC fits exactly is a tricky challenge. There’s latency to deal with, connectivity to physical devices, oftentimes without the ability to replace them, regulatory issues – this space has quite a few obstacles, which are also great barriers of entry and motes against competitors if one invests the effort here.
SaaS, CPaaS & open source: Build vs BuyTelehealth comes in different shapes and sizes.
Many of the CPaaS vendors have gone ahead and made themselves easy to use for telehealth, mainly by supporting HIPAA compliance requirements.
I’ve seen various telehealth solutions built on CPaaS while others build their own service from scratch using open source components. There is no single approach here that I can suggest, as each has its own advantages and challenges.
One of the biggest challenges in adopting CPaaS for telehealth is upholding the patient’s privacy. Functions of the CPaaS platform require it to know certain elements of PHI (Personal Health Information), especially if call recordings are implemented. At times, a telehealth platform may expose a patient name or other information to the CPaaS implementation. These invite additional security risks and may violate patient privacy laws. A BAA here helps, but may not be enough, since most patient privacy laws require to expose only the bare minimum that is needed to an external entity (in this case, the CPaaS vendor) when it comes to PHI.
Here. vendors should look at their core competencies and the actual requirements they have from their WebRTC infrastructure. And as always, my suggestion is to go with CPaaS unless there is a real reason not to.
Where can I help, if at all?
Online WebRTC courses, to skill up engineers on this technology
Consulting, mostly around architecture decisions and technology stack selection
Testing and monitoring WebRTC systems, via my role as Senior Director at Cyara (and the co-founder of testRTC)
The post WebRTC in telehealth: More than just HIPAA compliance appeared first on BlogGeek.me.
No. I am not ok
I’ve been meaning to write about a different topic about WebRTC, but somehow, this was more important.
There’s a war going on here where I live between Israel and Hamas. Or Israel and Gaza. Or Israel and the Palestiniens. Or Israel and Iran’s proxies. Or Israel and muslim extremists.
Or all of the above if we’re frank with ourselves.
We haven’t invited this war or wanted it, but it is what we need to face and deal with.
Others are explaining the situation better than I can on social media sites and in english. Here is one such example:
To those of you who reached out to me asking if I am ok, if me and my family are safe, I answered that we’re ok’ish mostly.
Well… I am not ok.
- At least 700 were brutally murdered
- Many of them civilians
- Many of them babies, children, women and the elderly
- Some of them are muslims (usually through rockets)
- Some of them foreigners here in Israel – working, living or just visiting
- Over 260 were butchered in an outdoor party. Many of them teenagers and young adults
- The number of murdered is likely to raise above 1,000
- At the size of Israel, this is bigger than 9/11 or pearl harbor event
- It is a huge milestone and likely a turning point
- Over 5,000 rockets have been fired on Israeli cities (might be more – might be less – who’s counting anymore?)
- There are more than 100 kidnapped Israelis in Gaza now. Taken from their homes in Israel. Again – babies, children, women and elderly among them
- Israeli parents and families still don’t know where their loved one are
- Are they wounded somewhere?
- Are they dead?
- Were they kidnapped and taken into Gaza?
- Are they being abused? Raped? Decapitated?
- Some find out from social media
- A story about people seeing their family members on live videos
- An elderly woman whose family found out she was murdered because the murderer decided to take a photo of her and publish it on her Facebook account
- My Facebook is filled with photos of missing family members. Mostly kids and young adults
- This is all for the world to see right there on social media if one cares to look at war crimes and atrocities committed by Hamas while the Gazans, Palestinitens and other extremist muslims across the globe cheer and gloat (again – directly on social media – just go and watch)
- These aren’t human beings. These are monsters
I. Am. Not. Ok.
- Yes. Physically, I am fine. We live at the center of Israel in relative safety at the moment
- Everything is relative in life
- We came back from a two week vacation in the US a day before the war started
- Yesterday, I went to the supermarket to buy supplies – we’re short on everything
- In the elevator I met a neighbor coming out. We greeted each other with “hi”. He noted that we don’t say “good morning” anymore. I agreed. We left without the so common “have a great day” greeting
- The supermarket was big and full of people for a Sunday morning
- It was also totally quiet. If you know Israelis, you know we’re a loud bunch. None of it took place there
- Everyone looked shell shocked and subdued on the outside. Looking more closely, you could see purpose. A parent telling his 20-year old child he wants to be called to the war – saying that while he is old, he wants to participate and help in any way he can
- A person near the cash registers, asking people to donate food and stuff to take to the soldiers
- And me? I consider myself sharp minded and grounded. I couldn’t find my shopping cart each time I went hunting for things to buy. Over and over again. I even came back and almost took a different cart to the astonishment of the pregnant lady and her husband standing next to it. Where was my mind wondering? Each and every time
No. I am not ok.
- We have two kids. Teenagers
- My son was on overdrive on the first day of the war. Hyperactive
- Probably in an attempt to process things
- That curbed down by the end of the day, and now he is silent and subdued
- Buries himself in his video games and his drawings
- My daughter, ever the silent type, stayed silent
- She went to sleep on that first day, telling me that one of her best friend’s brothers was likely injured and his parents are rushing to the hospital
- She woke up the next morning reading his name on a website as one of the first people announced dead. Murdered. Only 19 years old
- Before we could tell her the news as we heard it through the parents
- She spent the rest of yesterday going back and forth with the rest of her friends to that friend’s home. She will likely do that the rest of the week
- At the age of 16, she is now experiencing grief. Seeing it in the face. Seeing parents bury their murdered child
- What can I do with such reality?
- And me and my wife? We trudge along, each with his own way of dealing with it
- Thinking if and when to do what
- Is it the right time to shower or should we wait? Sirens and all
- Should we take our kids to this activity or that, or just cancel it for now
- And if our kids need to go somewhere, should we go along with them, for the good that will do, or not
- Is it enough to just close the door to the Mamad, or do we need to add an element that won’t let murdering palestinians open it from the outside while we’re inside?
- Mundane daily thoughts and decisions we need to make here
- It is hard to sleep at night
- Not sure it has anything to do with a jet lag coming back from the US and the 10 hour difference
- Or is it just the weird situation we’re in
- Probably that second option
I am not ok.
- We had sirens here. 5 of them so far I think. Not really counting
- Each time, this means running to our Mamad. Every house and apartment in Israel has such a thing if it were built in the last 20+ years
- This is a room that is built differently than the rest of the house
- It has concrete walls and ceiling
- A bomb shelter door and window made of heavy iron
- Complete with the ability to ceil it up for chemical weapons if needed
- This room is also my home office. If you’ve seen any of my videos or met me virtually, then you’ve seen this room
- The window there is now closed. There’s no point in opening it up until this is all over
- Once, I had to run in from a neighbor’s apartment, where we discussed matters related to the building. A decision I had to make – should I go stay in their Mamad or run home to be with my family so they worry a wee bit less
- We had a rocket fall a few 100’s of meters from our place. On the road. No one was wounded. We heard it really well
I am not ok.
- There’s an iron dome battery somewhere close. A few kilometers away I assume
- When it fires rockets we feel it and then we hear it
- It might be followed with a siren or not, depending on where the likely missiles are about to hit
- Then you hear the intercepts or the falling missiles. They sound different
I am not ok.
- We live next to a hospital. It is located some 2 kilometers from our place
- In the last two days, I’ve seen my share of military helicopters coming in and out, moving severely wounded people around as they spread them across hospitals in Israel
I am not ok.
- Hamas and the Palestinians are busy killing as many jews as they can indiscriminately
- Our government and legal system are bickering over the legality of stopping supplying electricity to Gaza. We give them life while they give us death
- What stupid world are we living in?
Physically? I am fine.
The rest? Not so much
–
If you know me or have been to this site before, then you know a bit about Israelis already.
We are here to create and innovate. To bring good to the world and to improve things.
In the 10+ years I’ve been running this blog, I shared my thoughts and helped my industry as much as I could. Many times, not asking for anything in return. It is what I do.
Two years ago, me and my other Israeli co-founders sold testRTC. Ever since I’ve been asking myself what I should do next.
One of my dreams recently has been to start teaching. Kids. Older ones. Show them the world of technology and entrepreneurship and what is possible. Be a mentor. Raise the next generation of creativity and innovation of Israelis.
I believe Israelis are a net positive to the world.
I act like this every day. I teach my kids in that way. I see that the floundering and ill equipped education system we have here in Israel does the same. There is no hatred in our teachings or in the way we raise our kids.
–
Palestiniens. Hamas. Extremist muslims.
How can they slaughter kids in cold blood? Murder whole families? Kill without discrimination whole communities? Then go and show it to the world on social media. And then praise it and celebrate on the streets.
This is inhumane.
In many ways, I see them as a net negative to the world.
I just can’t see it otherwise at the moment.
–
People who ask me what they can do to help – nothing. And everything.
Our dysfunctional government will find a way to help, and until then, the civilians here and the soldiers will figure it out. We always do. We don’t have a choice.
I don’t really need anything from you. We’re Israelis. We’ll survive. We have done so ever since the holocaust and we know we can only depend on ourselves. So thanks for asking, but I don’t need a thing at the moment.
- The solidarity flags and colors lighting places across the globe? That’s useless. Sorry
- You’ll switch gears over there saying we shouldn’t kill Palestiniens soon enough
- All the while having your governments (at least some of them) continue to fund the Palestiniens in one way or another, just ending up fueling their war against us
Here’s a few picks from the news:
- UK: Nir Bitton hits out at ‘brainwashed’ Celtic fans’ Palestine banners
- Germany: German citizens are celebrating the butchering and kidnapping of Jewish people in Israel
- US: Yosef Haddad, on The New York Times headlines (He is an Israeli Arab Christian. Follow him if you are interested in the Israeli-Palestinian conflict)
What can you do?
Understand that there aren’t really two sides to this story.
This conflict isn’t symmetrical in any way. It is between people who want to live and people who want to kill and ruin.
If you don’t believe me, then just go on social media and see what the Palestinians are doing. How they parade dead Israeli soldiers, small kids and elderly on the streets of Gaza for all their people to see and enjoy. This is the 21st century.
So no. I am not ok.
We will prevail. And in the meantime, I will be working. Different than usual, but still working. Still making my small and modest contribution to the world. Trying to touch and better those I interact with.
The post No. I am not ok appeared first on BlogGeek.me.
Fitting WebRTC in the brave new world of webcams, security, surveillance and visual intelligence
WebRTC has its place in surveillance and security applications. It isn’t core to these industries, but it is critical in many deployments.
Surveillance has become near and dear to my heart. I had a few vendors consult with me in the past. There are a few using testRTC. And then there’s the personal level. The system we have in our apartment building.
This got me to think quite a lot about WebRTC in surveillance tech lately.
Table of contents- Why my interest in surveillance cameras (and WebRTC)?
- Security and surveillance use cases in WebRTC
- Unique (?) challenges for WebRTC with camera hardware
- Ingress, egress and the concept of real time
- Mobile or desktop?
- The age of Artificial Intelligence in surveillance tech
- WebRTC isn’t core for surveillance but it is critical
I live in an apartment building here in Israel:
23 floors
91 apartments
2 main entrances (and another side one)
3 elevators
3 levels of underground parking
…
And yes. We have a surveillance camera system. Like all of the other apartment buildings in my neighborhood:
The view from my apartment on a nice dayA year ago, I was in charge of the vendor selection and upgrade process of our cameras. We switched from an analog system into a hybrid analog/IP one.
This month, we’re looking into upgrading an elevator camera to an IP one, as well as adding WiFi to our underground parking. Having a chat with one of the vendors we’re reaching out to, he was fascinated with my work on WebRTC and the potential of using it for application-less viewing of cameras.
I’ve had my share of meetings and dealings with vendors building different types of surveillance and security solutions. From private security solutions to large scale, enterprise visual intelligence ones. Obviously, the matter of these interactions were around WebRTC.
I am not an expert in surveillance, so take the market overview with a grain of salt
That said, I do know my way with WebRTC and where it fits nicely
Here are some of the things I learned over the years
Security and surveillance use cases in WebRTCI’ll start with the obvious – cameras, security and surveillance have multiple use cases. Some of them can be seen as classic to this domain while others slightly newer or a specialized niche. Each of these use cases is a world onto its own with its requirements from WebRTC and the types of solutions emerging in it.
Small scale / cheap multiple surveillance camerasThis is where I’d frame my own experience of our apartment building. A system that requires 32 or less video cameras, spread across the location, connected to a DVR (Digital Video Recorder) or an NVR (Network Video Recorder).
In essence, you go install the cameras in sensitive locations, wire them up (with an analog cable, IP or even wireless) to the media server that is located onsite as well. That media server is a DVR if it is a closed loop system or an NVR if you’re living in modern times. I’ll just refer to these two as xVR from here on.
Once there, you hook’em up to a local monitor that nobody goes and look at, as well as let the owner connect remotely from his PC or mobile phone.
Is WebRTC needed here? Not really.
Surveillance cameras today use RTP (and sometimes also RTSP). These are the new ones. Old ones are pure analog. They connect to that xVR media server, which handles them quite well today. It did so also before WebRTC came to our lives. The user then accesses the system to play the videos remotely using a dedicated application, which again, existed before WebRTC.
Since there’s no specific requirement to access this through a web browser, the use of WebRTC here is questionable.
You might say WebRTC would make things easier, but hey – if it ain’t broken, don’t fix it
These solutions are purchased from local vendors that install such systems. The buyer will usually reach out to an installer that will pick and choose the cameras and the surveillance system for the buyer. The buyer cares less about the technology and more about the local vendor’s ability to install and maintain the system when needed.
Enterprise / large scale surveillanceLarge scale surveillance systems for enterprises is more of the same as the small scale ones, but with a few main differences:
- There are more cameras
- There are also more sensors which we want to control and manage, likely using the same system. Think doors and managing employee entrance using keycards for example. While this is about surveillance and security, it is also about building automation
- This can go from a small scale building to as large as smart cities with lots of cameras – anywhere in-between that I bunch here are most likely multiple different markets with slightly different requirements
- We are likely to have a NOC, where security guards look at screens. Just like in the movies…
The two things that are making headways in this industry?
- Using AI to reduce the amount of people needed to look at surveillance monitors. This is done by adding vision smarts into cameras and the media servers (local or in the cloud), so that events and alerts can be filtered better
- To some extent, there’s also a requirement to use WebRTC in the NOC to be able to view in real time camera feeds without installing anything
Like the small scale solutions, here too the buyer will look for local installers. These will be the local integrators who bring the systems and install them. At times, the decision of brand will come from the buyer, though this is less likely. It is important to remember that a considerable part of the cost goes towards the setup and installation and not necessarily to the cost of the equipment itself.
Personal/home surveillanceThis one is the residential one. It is a B2C space where the buyer is a person buying a camera for his own home security. The decision is made on price or brand mostly.
Here you’ll find also solutions that make use of old smartphones and tablets as cameras, or something like the one we purchased a few years back when our kids were younger:
A digital peephole cameraHaving the ability for them to see who is outside our door when they were shorter.
Here too, the market is going into multiple directions:
- Home automation, connecting more sensors and devices in the home, some of them have cameras in them
- Surveillance and security, where today it seems at least here in Israel, that fingerprint door locks are all the rage
Where does WebRTC play here? It might make things smoother to develop for the companies, but this doesn’t seem to be the case.
One thing that goes through all use cases above, is the existence of another solution – the video doorbell. Taken into buildings, this becomes an intercom system, which again – can make use of WebRTC. And why? Because it needs bidirectional support for audio at the very least, making WebRTC a suitable alternative.
Personal securityA totally different niche is the one of personal security.
This manifests itself as apps (and services) people can use to increase their security while going about in their daily tasks. Some of these apps connect you to friends and family while others to personal security agents. The WebRTC requirement here is the same for all cases – be able to conduct voice and video calls in real time.
Taken more broadly from the personal level, the same can be implemented in campuses, cities, events, etc.
Unique (?) challenges for WebRTC with camera hardwareThere are some unique challenges for WebRTC when it comes to the surveillance space, and that’s mostly a matter of hardware.
- Costs
- Hardware costs money. Not just the devices themselves, but their installation. This also means that hardware costs needs to be kept low in most of these systems, which means less processing power available on the cameras themselves or the xDR devices
- To drive costs down, CPUs won’t be as performant as the ones found in smartphones or PCs for example, and they would almost always rely heavily on hardware video encoding
- Maintenance
- Many of these hardware systems come without subscription services. This means any firmware upgrades might or might not be available. It also means that such upgrades are sometimes clunky to get done on the devices, especially when they need to be handled remotely
- There’s a lot of physical maintenance as well involved. Cleaning lenses of cameras for example
- Technology leaps
- You purchase a system. It has cameras and a xDR. Time passes. A couple of years. You decide you need more cameras, replace an existing one, whatever
- There’s improvements that took place. The system you have might not even be able to deal with the new cameras available today, and purchasing old ones might not be possible or economical anymore
- We had this when the system in our residential building broke. The DVR had a hard drive malfunction – it didn’t record anything anymore
- It was impossible to replace, and buying a new old system wouldn’t be the right approach
- Some of the cameras lost quality due to their analog coax cables (I was told this is an issue), and the predicament was we’d lose more of these cables in the coming 2-5 years anyways
- So we had to shift the whole system to an IP based one. A technology leap
- While I don’t foresee a move away from IP, I am sure many of these systems will change in the coming years in ways that would leave some of the old hardware unusable
- Hybrid
- There are hybrid alternatives in this space. We ended up getting one for our building
- Due to the technology leaps, you end up with multiple types of sensors and cameras, from different generations and technologies
- The systems that cobbles it all together (the xDR in our case), can be one that manages them all
- Most installers won’t recommend it. It is mostly a necessary evil. Likely because it reduces the revenue of the installer and adds to the complexity of the installation and the system
Most of these issues won’t plague a software solution. But here, we end up in the real world simply because someone needs to go and install the physical cameras.
When figuring out the hardware platform to use, it is important to think of future trends and technology improvements that affect your implementation
In the case of surveillance, there’s WebRTC, future video codecs (AV1) and machine learning in the vision domain to think about. Probably also programmable photography that is bringing innovations to smartphones for a few years now
Ingress, egress and the concept of real timeWhere to place WebRTC in the solution?
Since I write a lot about WebRTC, and this article is mostly about WebRTC in surveillance markets, it is THE biggest question to answer here.
There are two different places, and both are suitable, but not necessarily together in the same system.
Surveillance needs real time. Sometimes.
Egress
In our own residential building, I seldom care about the live feed from the cameras. It is to check if the front door to the building is open or not, or if there’s some area that got dirty (usually dog pee). Then most of the time is spent rewinding to figure out who caused the problem. Nothing here is considered real time in nature or requires sub second latency.
Elsewhere, real time might be critical on the viewer side (egress), which brings with it the question of whether WebRTC fits here well.
Ingress
Web cameras that directly stream out WebRTC to the world (or the xDR). Is that a benefit? What’s the value of it versus the existing camera technologies used?
I am not quite for or against this, as I am not really sure here. I’d say that a benefit here can be in the fact that it makes the whole technology stack simpler if you end up using WebRTC end-to-end instead of needing to switch protocols from the camera to the viewer. Just remember here that rewind and playback will likely require something other than WebRTC.
The main advantage of WebRTC here might be the removal of the need to transcode and translate across protocols and codecs. It makes xDR software simpler to write and reduces a lot of their CPU requirements, making the systems lighter and cheaper (the xDR – not the camera itself).
One more thing to think of is cameras that also require bidirectional audio. Because a security guard wants to announce or warn perpetrators, or because this is a video doorbell. There, WebRTC fits nicely, though again – not mandatory (I’d still try using it there more than elsewhere).
Going to introduce WebRTC to a surveillance system? Great. Check first where exactly within the whole architecture WebRTC fits and ask yourself why
Mobile or desktop?Another important aspect of a surveillance system is where people go to watch the videos.
When we installed our own system, we were told that the mobile app is better than the PC app. In both, these were applications. But somehow for the consumers, it meant using the smartphone. It sucks. But yes – it sucks more on the desktop. Which is crazy, considering that what you’re trying to do is watch output coming from 4K cameras in order to identify people.
Then again, who is your customer?
If this is a large enterprise, where there’s going to be a fancy video wall of video feeds with a bored security guard looking at it, then should this be an application or would it be preferable to use a web application for it, with the help of WebRTC? It seems that much of the industry on the client side is looking for lightweight solutions that require less software installations, favoring browsers and… WebRTC.
And if you’re already doing WebRTC for one egress destination, you can use it for all others – browser and app based.
One more thing to consider – it is easier today to develop a web application than it is a native PC application. Cheaper and faster. Which means that supporting WebRTC if the desktop is your primary viewing device might be the right decision to make.
See if there’s a strong need for a zero-install or desktop viewing. This might well lead you towards WebRTC on the egress side
The age of Artificial Intelligence in surveillance techThe biggest driver in this industry is machine learning and artificial intelligence. And not necessarily the Generative AI kind, but rather the kind that deals with object classification.
The challenge with surveillance is watching the damn cameras. You need eyeballs on screens. The good old motion detection removes a lot of noise (or more accurately, static), but it leaves much to be desired.
One of the elevators in my building, along with the video you get most hours of the day – empty. The bar at the bottom with the blue stripes marks when there’s actual movement.
Using machine learning, it will be easier to search for dogs, people, colors, items and other tidbits to figure out times of interest in the thousands of hours of boring videos, as well as act as “Google search” on recorded video feeds.
Doing all that in the cloud is possible, but expensive and tedious – how do you ship all the video, decode it, process it again, etc.
Doing it on the edge, on the device itself (the camera or the xDR) is preferable, but requires new hardware, so requires another technology leap and refresh.
WebRTC isn’t core for surveillance but it is criticalThis is something to remember.
WebRTC isn’t core to surveillance. You don’t really need it to get surveillance cameras working, installed or connected to their xDR media servers. You don’t even need it to view videos – either “live” or as playback.
But, and that’s a big one – in some cases, having WebRTC is critical. Because your customer may want to be able to use web browsers and install nothing. He may want to be able to get bidirectional media. There might be a need to get video feeds that are at sub second latencies.
For these, WebRTC might not be a core competency, but they are critical to the successful delivery and deployment of your product. This translates into having a need to have that skill set in your team or be able to outsource it to someone with that skill set.
Where can I help, if at all?
Online WebRTC courses, to skill up engineers on this technology
Consulting, mostly around architecture decisions and technology stack selection Testing and monitoring WebRTC systems, via my role as Senior Director at Cyara (and the co-founder of testRTC)
The post Fitting WebRTC in the brave new world of webcams, security, surveillance and visual intelligence appeared first on BlogGeek.me.
Solving CPaaS vendor lock-in (as a customer and as a CPaaS vendor)
How to think and plan for CPaaS vendor lock-in when it comes to your WebRTC application implementation.
How can/should CPaaS vendors compete on winning customers? More than that, how can/should CPaaS vendors poach customers from other CPaaS vendors?
What prompted this article is the various techniques CPaaS vendors use and what they mean to customers – how should customers react to these techniques. I’ll focus on the Video API part of CPaaS – or to be more specific, the part that deals with WebRTC implementation.
Table of contents- What is CPaaS vendor lock-in?
- The innovation in WebRTC that CPaaS is “killing”
- CPaaS vendor poaching techniques and how to react to them
- Build vs Buy – my first preference is ALWAYS buy (=CPaaS)
For me CPaaS (or Communication Platform as a Service) is a service that lets companies build their own communication experiences in a flexible manner. Usually done via APIs and requires developers, but recently, also via lowcode/nocode interactions (such as embedding an iframe).
A CPaaS vendor ends up defining its own interface of APIs which his customers are using to create these communication experiences.
That API interface is proprietary. There is no standard specification for how CPaaS APIs need to look or behave. This means that if you used such an API, and you want to switch to another CPaaS vendor – you’re going to need to do all that integration work all over again.
Think of it like switching from an Android phone to an iPhone or vice versa:
- There’s a new interface you need to learn
- It might be similar since it practically used for doing the same things
- But it is also a bit “off”. The things you expect to be in one place are in another place
- The settings is done differently
- And the way you deal with the phone’s assistant (or Siri?) is different as well
- You need to install all of your apps from scratch
- Find them in the app store, download them, install them
- Set them up by logging in
- Some of them you need to purchase separately all over again
- Others you won’t find… and you’ll need to look for alternative apps instead – or decide not to use that functionality any longer
- The behavior will be different
- The background color of the apps
- They way you switch between screens is different
- The swipe “language” is also slightly different
In a way, you want the same experience (only better), but there’s going to be a learning curve and an adaptation curve where you familiarize yourself with the new CPaaS vendor and “make yourself at home”.
The vendor lock-in part is how much effort and risk will you need to invest and overcome in order to switch from one vendor to another – to call that other vendor your new home.
Vendor lock-in has 3 aspects to it in CPaaS:
- Difference in the API interface. That’s a purely technical one. Low risk usually, with varying degree of effort
- Behavioral differences. This has higher risk with unknown effort involved. While both CPaaS vendors do the “same” thing, they are doing it differently. And that difference is hidden behind how they behave. Your own application may rely on behavior that isn’t part of the standardized official interface and you will find out about it only once you test the migrated application on the new CPaaS vendor’s interface or later when things break in production
- Integration differences. There are things outside the official interface you might have integrated with such as logs collection, understanding and handling error codes and edge cases, ETL processes, security mechanisms, etc. These things are the ones developers usually won’t account for when estimating the effort in the beginning and will likely be caught late in the migration process itself
Vendor lock-in is scary. Not because of the technical effort involved but because of the risks from the unknowns. The more years and the more interfaces, scenarios and code you have running on a CPaaS vendor, the higher the lock-in and risk of migration you are at.
The innovation in WebRTC that CPaaS is “killing”Before WebRTC, we had other standards. RTP and RTCP came a lot before WebRTC.
We had RTMP, RTSP, SIP and H.323.
The main theme of all these standard specifications was that their focus has always been about standardizing what goes on over the network. They didn’t care or fret about the interface for the developer. The idea behind this was to enable using this standard on whatever hardware, operating system and programming language. Just read the spec and implement it anyway you like.
WebRTC changed all that (ignoring Flash here). We now have a specification where the API interface for the developer of a web application is also predefined.
WebRTC specifies what goes on the network, but also the JavaScript API in web browsers.
Here’s how I like explaining it in my slides:
One of the main advantages of WebRTC is that a developer who uses WebRTC in one project for one company can relatively easily switch to implement a different WebRTC project for another company. (that’s not really correct, but bear with me a little here)
We now could think of WebRTC just like other technologies – someone proficient in WebRTC is “comparable” to someone who worked with Node.js or SQL or other technologies. Whereas working with SIP or H.323 begs the question – which framework or implementation was used – learning a new one has its own learning curve.
Enter CPaaS…
And now the WebRTC API interface is no longer relevant. The CPaaS vendor’s SDK has its own interface indicating how things get done. And these may or may not bear any resemblance to the WebRTC API. Moreover – it might even try very hard to hide the WebRTC stack implementation from the developer.
This piece of innovation, where a developer using WebRTC can jump into new code of another project quickly is gone now. Because the interfaces of different CPaaS vendors aren’t standardized and don’t adhere to the standard WebRTC API interface (and they shouldn’t be – it isn’t because they are mean – it is because they offer a higher level of abstraction with more complex and complete functionality).
Not having the same interface across CPaaS vendors is one of the reasons we’ve started down this rabbit hole of exploring what CPaaS vendor lock-in is exactly.
CPaaS vendor poaching techniques and how to react to themEvery so often, you see one or more CPaaS vendors trying to grab a bit more market share in this space. Sometimes, it is about enticing customers who want to start using a CPaaS vendor. Other times it is focused on trying to poach customers from other CPaaS vendors.
When looking at the latter, here are the CPaaS vendor poaching techniques I’ve seen, how effective they are, and what you as a target company should think about them.
#1 – Feature list comparisonsThe easiest technique to implement (and to review) is the feature list comparison.
In it, a CPaaS vendor would simply generate and share a comparison table of how its feature set is preferable over the popular alternatives.
For a company looking to switch, this would be a great place to start. You can skim through the feature list and see exactly what’s there in the platform you are currently using and the one you are thinking of switching to.
When looking at such a list, remember and ask yourself the following questions:
- Is this list up to date? Oftentimes, these pages are created with big fanfare when a “poaching” or comparison project is initiated by the marketing department of a CPaaS vendor. But once done, it is seldom updated to reflect the latest versions (especially the latest version of the competitor). So take the comparison with a grain of salt. It is likely to be somewhat incorrect
- Check what your experience is with the vendor you are using versus how it is reflected in the comparison table. Does the table describe things as you see them?
- The features that look better “on paper” in this table for the vendor you plan on switching to. Do you need these features? Are they critical for you today or in the near future? Or are they just nice to have
- The “greens” on the vendor making the comparison – are they on par with the other vendor or just a less comprehensive implementation of it? (for example, support for group calls – both vendors may support it, but one can get you to X users with open mics in a group call while the other can do 10X users)
I’ve had my fare share of reading, writing and responding to comparison tables. A long time ago (pre-WebRTC), we received inputs that our competitor can do almost 10 times the number of concurrent calls we are able to do with much higher throughput. Obviously, we created a task force to deal with it. The conclusion was simple – the competitor didn’t measure the network time at all – just CPU time in the machine. We weren’t measuring the same thing and his choice of metric meant he always looked better
Your role in this? To read between the lines and understand what wasn’t written. Always remember that this isn’t an objective comparison – it is highly skewed towards the author of it (otherwise, he wouldn’t be publishing it)
#2 – Performance comparisonsHere the intent of the CPaaS vendor is to show that his platform is superior in its performance. It can offer better quality, at lower bitrates and CPU use for larger groups.
If a vendor does it on his own, then potential customers will immediately view the results as suspect. This is why most of them use third party objective vendors to do these performance comparisons for them (at a cost).
We’ve done this at testRTC a couple of times – some publicly shared (for this one, I’ve placed my own reputation and testRTC’s reputation on the frontline, insisting not to name the other vendors) and others privately done. It is a fun project since it requires working towards a goal of figuring out how different CPaaS vendors behave in different scenarios.
Zoom did this as well, comparing itself to other CPaaS vendors. Agora answered in kind with a series of posts comparing themselves back to Zoom (where Zoom didn’t look as shiny).
Just remember a few things when reading such comparisons:
- They were commissioned. They wouldn’t be published and shared if they weren’t showing what the CPaaS vendor wanted them to show
- For me, it is more interesting to see how the setup of the performance tests was done and what was left out or missed in the comparison to begin with
- The types of machines and browsers selected
- Scenarios picked
- Reference applications used for each vendor
- How measurements are done
- Which metrics are selected for the comparison
- Who the vendor was looking to compare himself to
- The CPaaS vendor usually helps and tweaks his own platform to fit the scenarios selected, while the competing vendors have no say in which of their applications or samples are used and if or how they are optimized for the scenario (hint: they aren’t)
In the end, the fact that a CPaaS vendor performs better than another in a scenario you don’t need says nothing for you. Make sure to give more weight to the results of actual scenarios relevant to you, and be sure you understand what is really being compared
#3 – Guides, how-to’s and success storiesHow do you make the migration of a customer from a different CPaaS vendor to your own? You write a migration document about it. A guide. Or a how-to. Or you get a testimonial or a success story from a customer willing to share publicly that he migrated and how life is so much better for him now.
These are mainly targeted at raising the confidence level for those who are contemplating switching, signaling them that the process isn’t risky and that others have taken this path successfully already.
As someone thinking of moving from one vendor to another, I’d seriously consider reaching out to the CPaaS vendor and ask the hard questions:
- How easy is the migration really is
- What challenges should one expect
- Are there any common issues that migrating customers have bumped into
- How many such customers do they have
- Can they reach out and ask one of those who migrated to have a quick direct conversation with
Anecdotes and recipes are nice. What you are after is having more data points.
Read these guides and success stories. Try reading between the lines in them. Check if you have any open questions and then ask these questions directly. Gather as much information as you can to get a clearer picture
#4 – Reference applicationsI wasn’t sure if this fits for migrating customers because it is a bit broader in nature. But here we are
In many cases, CPaaS vendors have reference applications available. Usually hosted on github. Just pull the code, compile, host and run it. You get an app that is “almost” ready for deployment.
You see how easy that was? Think how easy it is going to be to migrate to us with this great reference.
Remember a few things here:
- Your workflow is likely different enough from the reference app that there’s work to be done here
- In most cases, if you’ve built your application already on another vendor, using a reference app of another CPaaS vendor is close to impossible
- Reference apps are just references. They usually don’t cover many of the edge cases that needs handling
From my point of view, reference apps are nice to get a taste of what’s possible and how the API of a CPaaS vendor gets used. But that’s about it. They are unlikely to be useful during the migration process itself
#5 – Shims and adaptorsThey say imitation is the highest form of flattery. If that is true, then shims and adapters would fit well here.
In CPaaS, the most common one was supporting TwiML (that’s Twilio’s XML “language” for actions on telephony events). There’s also the idea/intent of having the whole API interface of another CPaaS vendor (or parts of it) supported directly by the poacher. The purpose of which is to make it easy to switch over.
Clearing things up a bit:
- CPaaS vendor A has an API interface
- CPaaS vendor B has a different API interface
- To make it easier to switch from vendor A to vendor B, vendor B decides to create a piece of software that translates calls of A’s API interface to B’s API interface. This is usually called a shim or an adaptor
The result? If you’re using vendor A, theoretically, you can take the shim created by vendor B and magically without any investment, you migrate to vendor B. Problem solved
While this looks great on paper, I am afraid it has little chance of holding up in the real world . Here’s why:
- The shim created is usually partial. Especially if vendor A offers a very rich interface (most vendors will, especially in the domain of video APIs and WebRTC)
- Like reference applications, these shims don’t take good care of edge cases. Why? Because they aren’t used by many customers less customers = less investment
- WebRTC is rather new, and CPaaS vendors have much to add, so every time vendor A updates his CPaaS and adds APIs to the interface – vendor B needs to invest in updating the shim. But is that even done once a shim is created? Or is it again, placed in the afterburner due the previous rule less customers = less investment
- Behavior. Same API interface doesn’t necessarily mean the vendor’s platforms behave the same on the network. These changes are hard to catch… and might be even harder to resolve
- Using a shim is nice, but if you want to use specific features available in vendor B’s interface – can you even do that if you’re doing everything via the shim? And is that the correct way to do things moving forward for you?
The thing is, that using a shim still means a ton of testing and headaches, but such that are hard to overcome.
If I had to switch between vendors, I’d ignore such shims altogether. For me they’re more of a trap than anything else.
Someone suggesting you use their shim for switching over to their CPaaS? Ignore them and just analyze what needs to be done as if there’s no shim available. You’ll thank me later
Build vs Buy – my first preference is ALWAYS buy (=CPaaS)We’ve seen 5 different techniques CPaaS vendors use to try and poach customers from one another. For the most part, they are of the type of “buyers beware”. And yet, we do need to migrate from time to time from one CPaaS vendor to another. Market dynamics might force us to do so or just the need to switch to a better platform or offering.
Does that mean it would be best to go it alone and build your own platform instead of using a third party CPaaS vendor?
No.
Vendor lock-in isn’t necessarily a bad thing. My first preference is always to adopt a CPaaS vendor. And if not to adopt one, then to articulate very clearly why the decision to build is made.
What should you do when you start using a CPaaS vendor to make the transition to another vendor (or to your own platform) smoother in the distant future? Here are a few things to consider.
- Limit the calls to the vendor’s API interface
- If you can make all of them from a single source file then great
- Even if not it is fine, but try not to call the vendor’s APIs and use their objects directly all over the place
- Having it all nicely compartmentalized will reduce the amount of changes needed during a migration
- Consider building an abstraction layer
- While I hate this one, it appeals to some
- Create your own abstraction of the communications capabilities you need
- Have that abstraction a “standardized” internal interface you follow
- Implement the integration with the vendor as a class/object of that interface
- This enables you to implement the next vendor or your own platform as yet another class/object for the same interface in the future at some point.
- Risky. As this probably will require architectural and design changes once that time comes, but it might still be the decision that can get your company to move forward
- Don’t use undocumented APIs and behaviors
- These will be harder to figure out in the future
- Making them harder to modify during a migration
- Assume there’s no simple solution
- No silver bullet or magic solution here
- Which means that time invested in catering for future multiple vendors or seamless migration paths is time wasted
- Try to make the decisions here ones that don’t take more resources or time today due to some unknown future need – you are more likely to make a mistake in these decisions than you are to succeed in it
The post Solving CPaaS vendor lock-in (as a customer and as a CPaaS vendor) appeared first on BlogGeek.me.
WebRTC cracks the WHIP on OBS
Open Broadcast Studio or OBS is an extremely popular open-source program used for streaming to broadcast platforms and for local recording. WebRTC is the open-source real time video communications stack built into every modern browser and used by billions for their regular video communications needs. Somehow these two have not formally intersected – that is […]
The post WebRTC cracks the WHIP on OBS appeared first on webrtcHacks.
WebRTC conferences – to mix or to route audio
How do you choose the right architecture for a WebRTC audio conferencing service?
Last month, Lorenzo Miniero published an update post on work he is doing on Janus to improve its AudioBridge plugin. It touched a point that I failed to write about for a long time (if at all), so I wanted to share my thoughts and views on it as well.
I’ll start with a quick explanation – Lorenzo is adding to Janus a lot of layers and flexibility that is needed by developers who are taking the route of mixing audio in WebRTC conferences. What I want to discuss here is when to use audio mixing and when not to use it. And as everything else, there usually isn’t a clear cut decision here.
Table of contents- What’s mixing and what’s routing in WebRTC?
- Audio processing tools available for us in WebRTC
- Mixing keeps the headaches away from the browser
- Routing gets you better flexibility
- Where the rubber hits the road – let’s talk use cases
- Which will it be? MCU or SFU for your next audio meeting?
Group calls in WebRTC can take different shapes and sizes. For the most part, there are 3 dominant architectures for WebRTC multiparty calling: mesh, mixing and routing.
I’ll be focusing on mixing and routing here since they scale well to 100’s or more users.
Let’s start with the basics.
Assume there’s a conversation between 5 people. Each of these people can speak his mind and the others can hear him speaking. If all of these people are remote with each other and we now need to model it in WebRTC, we might think of it as something like this illustration:
This is known as a mesh network. Its biggest disadvantage for us (though there are others) is the messiness of it all – the number of connections between participants that grows polynomially with the number of users. The fact that we need to send out the same audio stream to all participants individually is another huge disadvantage. Usually, we assume (and for good reasons) that the network available to us is limited.
The immediate obvious solution is to get a central media server to mix all audio inputs, reducing all network traffic and processing from the users:
This media server is usually called an MCU (or a conferencing bridge). Users here “feel” as if they are in a session with only a single entity/user and the MCU is in charge of all the headaches on behalf of the users.
This mixer approach can be a wee bit expensive for the service provider and at times, not the most flexible of approaches. Which is why the SFU routed model was introduced, though mostly for video meetings. Here, we try to enjoy both worlds – we have the SFU route the media around, to try and keep bitrates and network use at reasonable levels while trying to reduce our hosting and media processing costs as service providers:
The SFU has become commonplace and the winning architecture model for video meetings almost everywhere. Voice only meetings though, have been somewhere in-between. Probably due to the existence and use of audio bridges a lot before WebRTC came to our lives.
This begs the question then, which architecture should we be using for our audio in group calls? Should we mix it in our media servers or just route it around like we do with video?
Before I go ahead to try and answer this question, there’s one more thing I’d like to go through, and that’s the set of media processing tools available to us today for audio in WebRTC.
Audio processing tools available for us in WebRTCEncoding and decoding audio is the baseline thing. But other than that, there are quite a few media processing and network related algorithms that can assist applications in getting to the desired scale and quality of audio they need.
Before I list them, here are a few thoughts that came to mind when I collected them all:
- This list is dynamic. It changes a bit every year or so, as new techniques are introduced
- An example for this is active speaker detection, appearing in a paper a decade ago
- First adopted by Jitsi
- Then added to mediasoup by the team at hopin
- You can’t really use them all, all the time, for all use cases. You need to pick and choose the ones that are relevant to your use case, your users and the specific context you’re in
- We now have a machine learning based tool as well. We will have more of these in a year or two for sure
- It was a lot easier to compile this list now that we’ve finished recording and publishing all the lessons for the Higher-level WebRTC protocols course – we’ve covered most of these tools there in great detail
There is an RTP header extension for audio level. This allows a WebRTC client to indicate what is the volume that can be found inside the encoded audio packet being sent.
The receiver can then use that information without decoding the packet at all.
What can one do with it?
Decide if you need to decode the packet at all or just discard it if there’s no or little voice activity or if the audio level is too low (no one’s going to hear what’s in there anyway).
You can replace it with DTX (see below) or not forward the packet in a Last-N architecture (see below).
Not mix its content with other audio channels (it doesn’t hold enough information to be useful to anyone).
DTXIf there’s nothing really to send – the person isn’t speaking but the microphone is open – then send “silence” but with less packets over the network.
That’s what DTX is about, and it is great.
In larger meetings, most people will listen and not speak over one another. So most audio streams will just be “silence” or muted. If they aren’t muted, then sending DTX instead of actual audio reduces the traffic generated. This can be a boon to SFUs who end up processing less packets.
An SFU media server can also decide to “replace” actual audio it receives from users (because they have a low audio level in them or because of Last-N decisions he is making) with DTX data when routing media around.
PLCPackets are going to be lost, but there would be content that still needs to be played back to the user.
You can decide to play silence, a repeat of the last heard packet, lower its volume a bit, etc.
This can be done both on the server side (especially in the case of an MCU mixer) or on the client side – where such algorithms are implemented in the browser already. SFUs can ignore this one, mostly since they don’t decode and process the actual media anyway.
At times, these can be done using machine learning, like Google’s proprietary WaveNetEq, which tries to estimate and predict what was in the missing packet based on past packets received.
Packet loss concealment isn’t great at all times, but it is a necessary evil.
RTX & NACKTheoretically, you could use retransmissions for lost packets.
WebRTC does that mostly for video packets, but this can also find a home for audio.
It is/was a rather neglected area because PLC and Opus inband FEC techniques worked nicely.
For the time being, you’re likely to skip this tool, but it is one I’d keep an eye on if I were highly interested in audio quality advancements.
FEC and REDForward Error Correction is about sending redundant data that can be used to reconstruct lost packets. Redundancy coding is what we usually do for audio, which is duplicating encoded frames.
Audio bandwidth requirements are low, so duplicating frames doesn’t end up taxing much of our network, especially in a video call.
This approach enables us at a “low cost” to gain higher resiliency to packet losses.
This can be employed by the client sender, or even from the server side, beefing up what it received – both as an SFU or an MCU.
Check Philipp Hancke’s tal at Kranky Geek about Advanced in Audio Codecs
Then there’s the nuances and headaches of when to duplicate and how much, but that’s for another article.
Last-NA known technicality in WebRTC’s implementation is that it only mixes the 3 loudest incoming audio channels before playing back the audio.
Why 3? Because 2 wasn’t enough and 4 seemed unnecessary is my guess. Also, the more sources you mix, the higher the noise levels are going to be, specially without good noise suppression (more on that below)
Well… Google just decided to remove that restriction. Based on the announcement, that’s because the audio decoding takes place in any case, so there’s not much of a performance optimization not to mix them all.
So now, you can decide if you want to mix everything (which you just couldn’t before) or if you want to mix or route only a few loudest volume (or most important) audio streams if that’s what you’re after. This reduces CPU and network load (depending on which architecture you are using).
Google Meet for example, is employing Last-3 technique, only sending up to 3 loudest audio streams to users in a meeting.
Oh, and if you want to dig deeper into the reasoning, there’s a nice Jitsi paper from 2016 explaining Last N.
Noise suppression: RNNoise and other machine learning algorithmsNoise suppression is all the rage these days.
RNNoise is a veteran among the ML-based noise suppression algorithms that is quite popular these days.
Janus for example, have added it to their AudioBridge and implemented optional RNNoise logic to handle channel-based noise suppression in their MCU mixer for each incoming stream.
Google added this in their Google Meet cloud – their SFU implementation passes the audio to dedicated servers that process this noise suppression – likely by decoding, noise suppression and encoding back the audio.
Many vendors today are introducing proprietary noise suppression to their solutions on the client side. These include Krisp, Dolby, Daily, Jitsi, Twilio and Agora – some via partnerships and others via self development.
Mixing keeps the headaches away from the browserWhy use an MCU for mixing your audio call? Because it takes all the implementation headaches and details away from the browser.
To understand some of what it entails on the server though, I’d refer you again to read Lorenzo’s post.
The great thing about this is that for the most part, adding more users means throwing more cloud hardware on the problem to solve it. At least up to a degree this can work well without thinking of scaling out, decentralization and other big words.
It is also how this was conducted for many years now.
Here are the tools I’d aim for in using for an audio MCU:
ToolUse?ReasoningAudio levelDecoding less streams will get higher performance density for the server. Use this with Last-N logicDTXBoth when decoding and while encodingPLCOn each incoming audio stream separatelyRTX & NACKTo early to do this todayFEC and REDToday, for an MCU, this would be rare to see as a supported featureConsider on outgoing audio streams; as well as enable for incoming streams from devicesLast-NLast-3 is a good default unless you have a specific user experience in mind (see below examples)Noise suppressionOn incoming channels, those that passed Last-N filtering, to clean them up before mixing the incoming streams togetherThings to note with an audio MCU, is that the MCU needs to generate quite a few different outgoing streams. For 10 participants with 4 speakers (at Last-4 configuration), it would be something like this:
We have 5 separate mixers at play here:
- 1 mixing all 4 active speakers
- 4 mixing only 3 out of the 4 each time – we don’t want to send the person speaking his own audio mixed in the stream
Why do we use an SFU for audio conferences? Because we use it for video already… or because we believe this is the modern way of doing things these days.
When it comes to routing audio, the thing to remember is that we have a delicate balance between the SFU and the participants, each playing a part here to get a better experience at the end of the day.
Here are the tools I’d use for an audio SFU:
ToolUse?ReasoningAudio levelWe must have this thing implemented and enabled, especially since we really really really want to be able to conduct Last-N logic and not send each user all audio channels from all other participantsDTXWe can use this to detect silence as well here (and remove from Last-N logic). On the sending logic, the SFU can decide to DTX the channels in Last-N that are silent or at a low volume to save a bit of extra bandwidth (a minor optimization)PLCNot needed. We route the audio packets and let the participants fix any losses that take placeRTX & NACKTo early to do this todayFEC and REDThis can be added on the receiver and sender side in the SFU to improve audio quality. Adding logic to dynamically device when and how much redundancy based on network conditions is also an advantage hereLast-NLast-3 is a good default. Probably best to keep this at most at Last-5 since the decision here means more CPU use on the participants’ sideNoise suppressionNot needed. This can be done on the participants’ sideIn many ways, an audio SFU is simpler to implement than an audio MCU, but tweaking it just right to gain all the benefits and optimizations from the client implementation is the tricky part.
Where the rubber hits the road – let’s talk use casesAs with everything else I deal with, which approach to use depends on the circumstances. One of the main deciding criteria in this case is going to be the use case you are dealing with and the scenario you are solving this for.
Here are a few that came to mind.
Gateway to the old worldThe first one is borderline “obvious”.
Before WebRTC, no one really did an audio conference using an SFU architecture. And if they did, it was unique, proprietary and special. The world revolved and still revolves around MCU and mixing audio bridges.
If your service needs to connect to legacy telephony services, existing deployments of VoIP services running over SIP (or god forbid H.323), connect to a large XMPP network – whatever it may be – that “other” world is going to be running as an MCU. Each device is likely capable of handling only one incoming audio stream.
So trying to connect a few users from your service (no matter if you are using an SFU or an MCU) would need to mix these users when connecting them to the legacy service.
Video meetings with mixed audioThere are services that decide to use an SFU to route video streams and an MCU for the audio streams.
Sometimes, it is because the main service started as an audio service (so an audio bridge was/is at the heart of the service already) and video was bolted on the platform. Sometimes it is because gatewaying to the old world is central to the service and its mindset.
Other times, it is due to an effort to reduce the number of audio streams being sent around, or to reduce the technical requirements of audio only participants.
Whatever the reason, this is something you might bump into.
The big downside of such an approach is the loss of lip synchronization. There is no practical way you can synchronize a single audio stream that represents mixed content of multiple video streams. In fact, no lip synchronization with any of the video streams takes place…
Usually, the excuse I’ll be hearing is that the latency difference isn’t noticeable and no one complained. Which begs the question – why do we bother with lip synchronization mechanisms at all then? (we do because it does matter and is noticeable – especially when the network is slightly bumpier than usual)
Experience the crowdThink of a soccer game. 50,000 people in a stadium. Rawring when there’s a goal or a miss.
With Last-3 audio streams mixed, you wouldn’t be hearing anything interesting when this takes place “remotely” for the viewers.
The same applies to a virtual online concert.
Part of the experience you are trying to convey is the crowds and the noises and voices they generate.
If we’re all busy reducing noise levels, suppressing it, picking and choosing the 2-3 voices in the crowd to mix, then we just degrade the experience.
Crowds matter in some scenarios. And keeping their experience properly cannot be done by routing audio streams around. Especially not when we’re starting to talk about hundreds of more active participants.
This case necessitates the use of MCU audio bridging. And likely a distributed approach the moment the numbers of users climb higher.
Metaverse and spatial audioThe metaverse is coming. Or will be. Maybe. Now that Apple Vision Pro is upon us. But even before that, we’ve seen some metaverse use cases.
One thing that comes to mind here is the immersion part of it, which leads to spatial audio. The intent of hearing multiple sounds coming from different directions – based on where the speaker is.
This means several things:
- For each user, the angle and distance (=volume level) of each other person speaking is going to be different
- That Last-3 strategy doesn’t work anymore. If you can distinguish directionness and volume levels individually, then more sources might need to be “mixed” here
Do you do that on the client side by way of an SFU implementation, or would it be preferable to do this in an MCU implementation?
And what about trying to run concerts in the metaverse? How do you give the notion of the crowds on the audio side?
These are questions that definitely don’t have a single answer.
In all likelihood, in some metaverse cases, the SFU model will be the best architectural approach while in others an MCU would work better.
Recording it allNot exactly a use case in its own right, but rather a feature that is needed a lot.
When we need to record a session, how do we go about doing that?
Today, in at least 99% of the time that would be by mixing all audio and video sources and creating a single stream that can be played as a “regular” mp4 file (or similar).
Recording as a single stream means using an MCU-like solution. Sometimes by implementing it in a headless browser (as if this is a silent participant in the session) and other times by way of dedicated media servers. The result is similar – mixing the multiple incoming streams into a single outgoing one that goes directly to storage.
The downside of this, besides needing to spend energy on mixing something that people might never see (which is a decision point to which architecture to pick for example), is that you get to view and hear only a single viewpoint of a single user – since the mixed recording is already “opinionated” based on what viewpoint it took.
We can theoretically “record” the streams separately and then play them back separately, but that’s not that simple to achieve, and for the most part, it isn’t commonplace.
A kind of a compromise we see today with professional recording and podcast services is to record by mixed and separated audio streams. This allows post production to take either based on the mixing needs, but done manually.
Which will it be? MCU or SFU for your next audio meeting?We start with this, and we will end with this.
It depends.
You need to understand your requirements and from there see if the solution you need will be based on an MCU, and SFU or both. And if you need help with figuring that out, that’s what my WebRTC courses are for – check them out.
The post WebRTC conferences – to mix or to route audio appeared first on BlogGeek.me.
10 Years of webrtcHacks – merch and stats
webrtcHacks celebrates our 10th birthday today 🎂. To commemorate this day, I’ll cover 2 topics here: Our new merch store Some stats and trends looking back on 10 years of posts We have the Merch In the early days of webrtcHacks, co-founder Reid Stidolph ordered a bunch of stickers which proved to be extremely popular. […]
The post 10 Years of webrtcHacks – merch and stats appeared first on webrtcHacks.
WebCodecs, WebTransport, and the Future of WebRTC
Explore the future of Real-Time Communications with WebrtcHacks as we delve into the use of WebCodecs and WebTransport as alternatives to WebRTC's RTCPeerConnection. This comprehensive blog post features interviews with industry experts, a review of potential WebCodecs+WebTransport architecture, and a discussion on real-time media processing challenges. We also examine performance measurements, hardware encoder issues, and the practicality of these new technologies.
The post WebCodecs, WebTransport, and the Future of WebRTC appeared first on webrtcHacks.
Pages
Using the greatness of Parallax
Phosfluorescently utilize future-proof scenarios whereas timely leadership skills. Seamlessly administrate maintainable quality vectors whereas proactive mindshare.
Dramatically plagiarize visionary internal or "organic" sources via process-centric. Compellingly exploit worldwide communities for high standards in growth strategies.
Wow, this most certainly is a great a theme.
Company name
Yet more available pages
Responsive grid
Donec sed odio dui. Nulla vitae elit libero, a pharetra augue. Nullam id dolor id nibh ultricies vehicula ut id elit. Integer posuere erat a ante venenatis dapibus posuere velit aliquet.
Typography
Donec sed odio dui. Nulla vitae elit libero, a pharetra augue. Nullam id dolor id nibh ultricies vehicula ut id elit. Integer posuere erat a ante venenatis dapibus posuere velit aliquet.